
Developer supply chain security is the practice of protecting the tools, dependencies, workflows, and credentials used to build, test, deploy, and operate software.
For many small teams, cloud server security starts with firewalls, SSH keys, operating system updates, and backups. Those are still important. But modern software rarely reaches a server directly from one developer’s laptop. Code passes through package managers, Git repositories, build tools, CI/CD workflows, containers, deployment scripts, secrets, SSH keys, and third-party developer tools.
That chain is now part of the security boundary.
Raff Technologies is relevant because many developers and small teams use cloud VMs as development, staging, and production environments. A secure VM is not only about the machine itself. It is also about what is allowed to deploy to it, which tools can reach it, and which credentials exist between the codebase and the server.
This guide explains where developer supply chain risk appears, how compromised tools can affect cloud servers, and how to build a practical protection framework without turning a small team into an enterprise security department.
Cloud server security starts before code reaches the server
A cloud server can be patched, monitored, and properly configured, but still be exposed through the path that delivers code to it.
That path might include:
- A developer laptop
- A Git repository
- Package dependencies
- IDE extensions
- Build scripts
- CI/CD workflows
- Docker images
- Deployment keys
- SSH credentials
- Environment variables
- Cloud API tokens
If one part of that chain is compromised, the server can become reachable indirectly. An attacker may not need to break into the VM through SSH. They may only need to steal a deployment token, modify a workflow file, poison a dependency, or access a secret used by the build pipeline.
That is why developer supply chain security matters. It protects the path between code creation and production infrastructure.
For small teams, this can feel abstract until the first incident happens. A leaked .env file, a public SSH key, an overpowered GitHub token, or a risky package update can create real exposure. The goal is to build simple guardrails before those mistakes become production problems.
For broader infrastructure basics, this guide should link naturally to Cloud Security Fundamentals.
The most common risk is not the server itself
Many teams secure the server but forget the tools around it.
A cloud VM may have a strong password policy, SSH key access, updates, and a firewall. But if the deployment workflow stores production secrets too broadly, the server remains exposed. If any developer tool can read tokens or modify deployment scripts, the server inherits that risk.
Common supply chain risk points include:
- Dependencies installed from public package registries
- Scripts that run automatically during install or build
- CI/CD workflow files that can be changed in pull requests
- Secrets stored in repository settings or plain files
- Personal access tokens with broad permissions
- Docker images pulled from untrusted sources
- SSH keys reused across dev, staging, and production
- IDE plugins or browser extensions with excessive access
- Developer machines with access to production credentials
The server is only one layer. The workflow around the server is another layer.
A practical security mindset asks: what can reach production, and what can change the code that reaches production?
That question usually reveals more risk than a basic server checklist.
Dependencies can become part of the attack surface
Modern software depends on third-party packages.
That is normal. No team writes every library from scratch. But every dependency introduces a trust relationship. The package may be maintained by a strong team, a single developer, an abandoned project, or an account that could be compromised.
Dependency risk can appear through:
- Malicious new packages
- Compromised maintainer accounts
- Typosquatting package names
- Abandoned dependencies
- Vulnerable versions
- Install scripts with unexpected behavior
- Transitive dependencies several layers deep
The practical answer is not “never use dependencies.” That is unrealistic. The answer is to reduce blind trust.
Small teams can improve dependency security by using lockfiles, reviewing major updates, avoiding unknown packages for critical paths, pinning versions where appropriate, and removing libraries that are no longer needed.
This matters for cloud servers because dependencies often run during build, deployment, or application startup. If a dependency can execute code, access environment variables, or change build output, it can affect what reaches the VM.
Dependency hygiene is infrastructure hygiene.
CI/CD workflows are privileged infrastructure
CI/CD pipelines are not just automation. They are privileged systems.
A deployment workflow may be able to pull code, install dependencies, access secrets, build artifacts, connect to a server, restart services, push containers, or run database migrations. That makes the pipeline powerful.
If a workflow can deploy to production, it should be treated as part of production security.
CI/CD risk often appears when workflows are too permissive:
- Any branch can trigger deployment
- Pull requests can access sensitive secrets
- Tokens have broad repository or cloud permissions
- Workflow files can be changed without review
- Deployment scripts run untrusted code
- Logs expose environment variables
- Build jobs reuse long-lived credentials
- Production deployment happens without human approval
The safer pattern is to limit what each workflow can do.
A test workflow does not need production secrets. A documentation build does not need SSH access. A pull request from an external contributor should not receive deployment credentials. A production deploy should require more control than a lint check.
For small teams, this distinction is often the biggest improvement: separate testing workflows from deployment workflows.
Secrets are the bridge between code and infrastructure
Secrets are often the shortest path from a codebase to a cloud server.
A secret might be an SSH private key, API token, database password, cloud credential, registry token, Git provider token, or webhook secret. If it allows code to deploy, connect, or authenticate, it needs careful handling.
Common secret mistakes include:
- Storing secrets in source code
- Committing
.envfiles - Reusing the same SSH key across environments
- Giving CI/CD tokens more permissions than needed
- Keeping old tokens active after people leave
- Sharing production credentials in chat tools
- Allowing secrets to appear in logs
- Using one credential for development and production
A better approach is to scope secrets by environment.
Development secrets should not unlock production. Staging secrets should not unlock production databases. CI/CD deployment keys should do only what the deployment requires. If a key is exposed, the damage should be limited.
This is also where rotation matters. A secret that has existed for years and is used everywhere becomes difficult to replace. Smaller, scoped secrets are easier to rotate when something goes wrong.
SSH access should be narrow and intentional
SSH is powerful because it gives direct server access.
That power is useful for administration, troubleshooting, and deployment. It also creates risk when access is too broad.
A good cloud server access model avoids treating SSH as a shared team shortcut. Instead, access should be deliberate:
- Use SSH keys instead of reusable passwords
- Give each person their own key
- Remove old keys when access is no longer needed
- Avoid sharing one root credential across the team
- Disable unnecessary direct root access where possible
- Separate development, staging, and production SSH keys
- Restrict deployment keys to deployment tasks
- Keep emergency access separate from daily access
 For small teams, the simplest improvement is individual access. If everyone uses the same key, nobody knows who did what and rotation becomes painful. If each person has their own key, access can be removed cleanly.
For small teams, the simplest improvement is individual access. If everyone uses the same key, nobody knows who did what and rotation becomes painful. If each person has their own key, access can be removed cleanly.
SSH should be treated like production access, not convenience.
A decision framework for developer supply chain risk
Use this framework to decide what level of protection your team needs.
| Situation | Risk level | Recommended protection |
|---|---|---|
| Personal test project | Low | Basic SSH keys, no production secrets, simple dependency review |
| Public demo app | Low to medium | Separate test credentials, lockfiles, limited deployment access |
| Small production website | Medium | Staging environment, scoped secrets, reviewed deploy workflow |
| Database-backed app | Medium to high | Separate database credentials, backups, limited CI/CD permissions |
| Customer-facing SaaS | High | Separate dev/staging/prod, protected branches, required reviews |
| CI/CD deploys to production | High | Least-privilege tokens, workflow review, deployment approvals |
| Multiple developers have server access | High | Individual SSH keys, access review, offboarding process |
| AI agents or automation modify code | Medium to high | Isolated dev environment, human review, no production secrets |
| Open-source contributors submit PRs | High | No secrets in untrusted PR workflows, strict workflow permissions |
The key question is: what can change production, and who or what can control that path?
If only one developer manually deploys a test project, the risk is lower. If a CI/CD workflow can deploy customer-facing software with production secrets, the risk is much higher.
The protection level should match the blast radius.
Separate development, staging, and production whenever possible
Environment separation is one of the simplest ways to reduce supply chain risk.
A development VM is where code can change quickly. A staging VM is where changes can be tested in a production-like environment. A production VM is where customer-facing workloads run.
These environments should not all share the same credentials.
A safer structure looks like this:
| Environment | Purpose | Access level |
|---|---|---|
| Development | Experiment, build, test, agent-assisted changes | Low-risk credentials |
| Staging | Validate changes before production | Production-like, but isolated |
| Production | Serve real users and data | Strict, reviewed, limited access |
This structure prevents a mistake in development from immediately becoming a production incident.
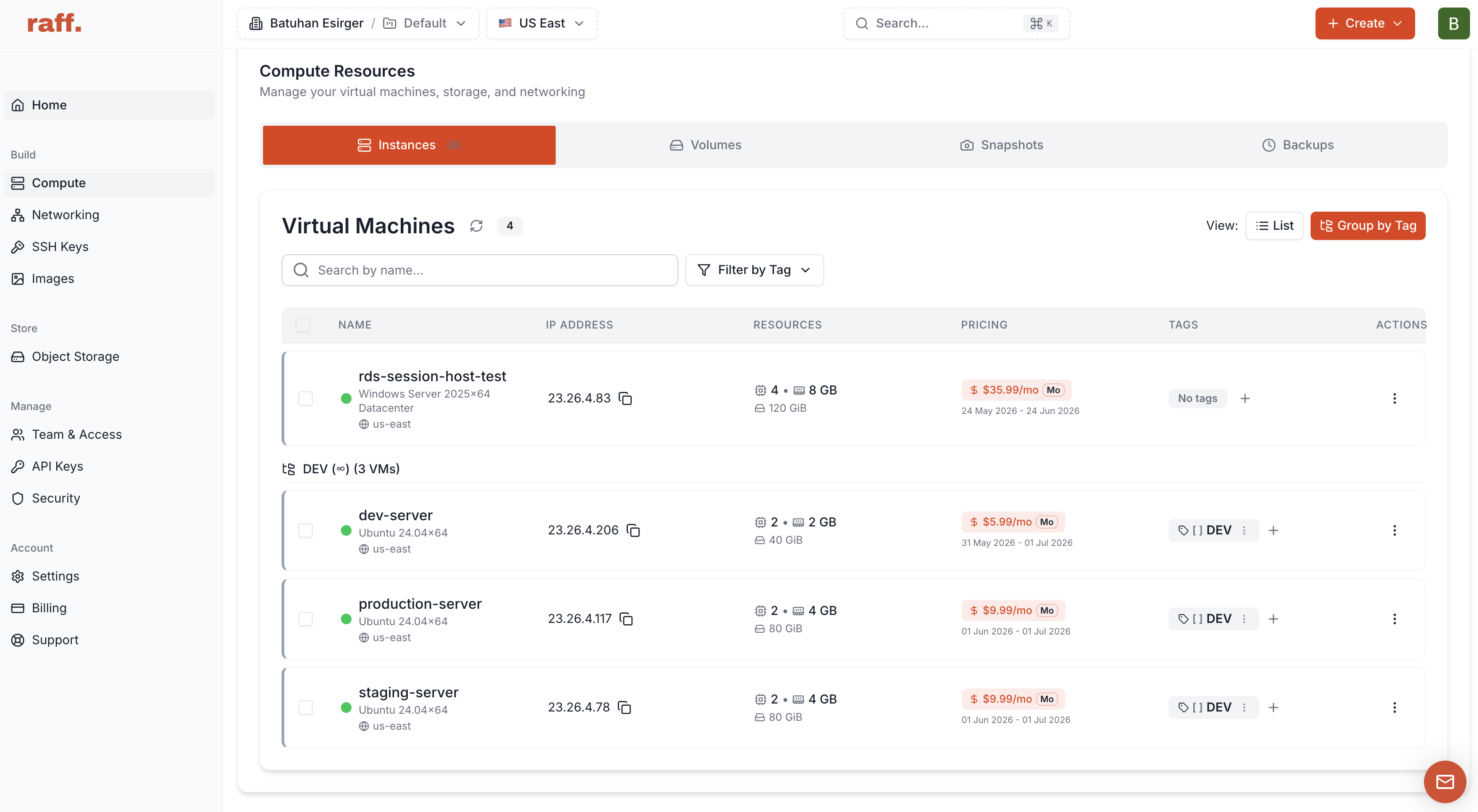
It also helps with AI-assisted development. If an AI coding agent, automation script, or junior developer works in a development environment, their mistakes stay contained. Production deployment remains a human-controlled decision.
For related AI workflow planning, link to AI Coding Agents and Cloud Dev Environments.
AI-assisted development increases the need for boundaries
AI coding agents and automation tools can improve productivity, but they also make boundaries more important.
An AI assistant may edit files, suggest commands, generate workflow changes, update dependencies, or prepare pull requests. That does not mean it should have production access. It means the environment around it should be designed carefully.
Safer AI-assisted development patterns include:
- Run agent work in a development VM
- Use test credentials only
- Keep production secrets out of the workspace
- Review workflow file changes manually
- Review dependency changes carefully
- Require human approval before deployment
- Keep staging and production separate
 This is not about mistrusting AI. It is about using normal engineering discipline. Any tool that can change code should operate inside a boundary.
This is not about mistrusting AI. It is about using normal engineering discipline. Any tool that can change code should operate inside a boundary.
A clean cloud dev environment gives the agent a place to work. Human review decides what moves forward.
Raff context for supply chain-safe cloud workflows
Raff VMs can help small teams create cleaner boundaries between development, staging, and production.
A team might use one Raff Linux VM as a development or testing environment, another as staging, and a separate VM for production. This makes the deployment path easier to reason about. Code can be tested before it reaches the production server, and production secrets do not need to exist in every workspace.
For lightweight development or testing, Raff’s 2 vCPU / 2 GB RAM / 50 GB NVMe General Purpose plan can be a practical starting point. For staging environments with databases, Docker Compose stacks, or self-hosted tools, Raff’s HiMem options may be more suitable. For production workloads, teams can choose a larger General Purpose or CPU-focused plan depending on the workload.
Across visible Raff VM plans, users get resize support, NVMe storage, unmetered bandwidth, standard 3 Gbps port speed, and 1 IPv4 with optional IPv6. This gives teams a simple way to start with separated environments and resize as the workflow grows.
The design rationale is practical: secure workflows should not require enterprise complexity. Even a small team can separate development from production, limit secrets, and use cloud VMs as clear infrastructure boundaries.
Common mistakes that expose cloud servers
The first mistake is storing secrets in the repository.
Even private repositories should not be treated as secret stores. Repositories are copied, cloned, backed up, integrated, and accessed by tools. Secrets belong in controlled secret systems or environment-specific settings.
The second mistake is letting test workflows access production credentials.
A workflow that runs on every pull request should not have the same access as a production deployment workflow.
The third mistake is reusing SSH keys everywhere.
One key for every server is convenient until it must be rotated. Separate keys by user, environment, and purpose.
The fourth mistake is ignoring workflow file changes.
CI/CD workflow files can be as sensitive as application code. If someone changes what the pipeline runs, they may change what gets deployed or what secrets are exposed.
The fifth mistake is trusting dependencies without review.
Package updates are useful, but they should not be automatic for critical production paths without some level of review, testing, or version control.
Best practices for protecting cloud servers from supply chain risk
Separate environments early
Use separate development, staging, and production environments when the workload becomes customer-facing. This limits the impact of mistakes and compromised tools.
Give CI/CD the least access it needs
A pipeline should not have broad permissions by default. Give each workflow only the access required for its specific job.
Review workflow changes like infrastructure changes
CI/CD configuration controls how code moves to servers. Treat workflow changes as security-sensitive.
Keep production secrets out of development
Development environments should use test credentials. Production credentials should be limited, rotated, and protected.
Pin and review important dependencies
Use lockfiles, review major updates, and avoid unknown packages in critical paths. Dependency updates should be visible, not invisible.
Use individual SSH keys
Avoid shared server access. Individual keys make access easier to audit, revoke, and rotate.
Resize security boundaries as the team grows
A solo project may begin simply. A production team needs stronger boundaries, more review, and clearer separation between environments.
Supply chain security is practical infrastructure hygiene
Developer supply chain security is not only for large enterprises.
Any team that uses dependencies, Git workflows, deployment scripts, CI/CD secrets, SSH keys, or cloud servers has a supply chain. The question is whether that chain is visible and controlled, or accidental and over-permissioned.
The safest path is practical: separate environments, limit secrets, review workflow changes, control SSH access, and choose cloud server boundaries that match the workload’s risk.
For broader infrastructure planning, read Cloud Security Fundamentals. For AI-assisted development boundaries, continue with AI Coding Agents and Cloud Dev Environments. For choosing the right VM size for each environment, read Raff General Purpose VM Plans Explained.
If your team is moving code from Git to cloud servers, Raff’s Linux VMs give you a simple way to separate development, staging, and production environments while keeping the infrastructure clear and resizeable.