

A 48-hour MVP infrastructure stack is a minimal cloud setup that helps teams launch and validate a product within two days using simple compute, managed data services, and lightweight operational tooling.
At Raff Technologies, we see this pattern often: early teams lose momentum not because their idea is weak, but because their infrastructure becomes heavier than the product itself. Before the first real user arrives, they are already debating Kubernetes, multi-service deployments, complex CI/CD flows, and cloud architectures designed for traffic they do not yet have.
That is usually the wrong first battle.
If your MVP needs a DevOps team before it has users, the stack is probably too complicated. Raff Technologies supports 10K+ deployed VMs, 1,000+ customers, and cloud servers that can be deployed in seconds, which gives us a practical view into what early teams actually need when they are trying to ship quickly.
This guide explains what a 48-hour MVP infrastructure stack should include, what it should avoid, and how to decide when your product has earned the next layer of complexity.
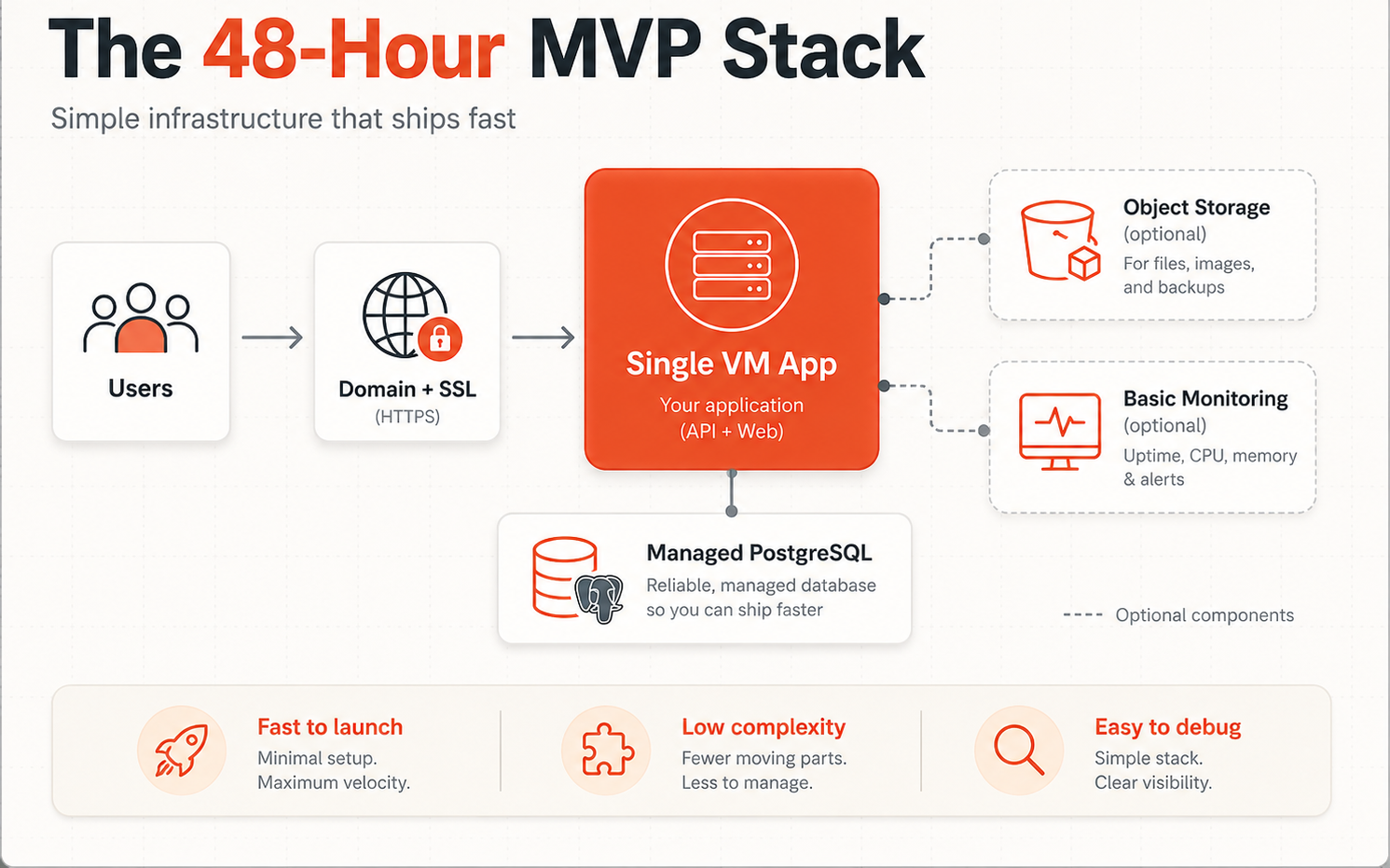 Suggested placement: after the opening block. This visual introduces the whole MVP stack before the reader enters the detailed explanation.
Suggested placement: after the opening block. This visual introduces the whole MVP stack before the reader enters the detailed explanation.
The real MVP infrastructure problem is not scale
Most MVPs do not fail because the first version was hosted on infrastructure that was too simple.
They fail because the team spends too much time building around imaginary scale instead of real usage.
At the MVP stage, your primary risk is usually not that the product receives millions of requests overnight. Your primary risk is that you do not launch fast enough to learn whether users care. That changes the infrastructure decision completely.
A mature product optimizes for resilience, redundancy, automation, separation of concerns, compliance, and predictable scaling. An MVP optimizes for speed, clarity, and reversibility.
Those are different jobs.
A simple stack lets one developer understand the whole system. They know where the app runs, where the logs are, where the database lives, how deployment works, and what to check when something breaks. That clarity matters more than architectural elegance when the product is still trying to prove demand.
The question is not:
What stack would look impressive to another engineer?
The better question is:
What stack gives us the best chance of launching this week and learning from real users?
That question usually leads to a smaller, better infrastructure plan.
What a 48-hour MVP stack should include
A practical 48-hour MVP stack should include only the infrastructure required to make the product usable, reachable, and maintainable.
For most web-based MVPs, that means:
- One application runtime
- One primary database
- A real domain
- SSL
- Basic deployment
- Basic monitoring
- Backups or snapshots
- Optional object storage if the product handles files
That is enough for a surprising number of early products.
The stack can support a SaaS dashboard, a marketplace prototype, an internal tool, a developer product, a content platform, an API service, or a customer portal. What matters is not the exact framework. The framework could be Next.js, Django, Laravel, Rails, Node.js, FastAPI, Go, or something else your team already understands.
The more important decision is the operational shape.
A good MVP stack should be easy to answer in one sentence:
One app, on simple compute, connected to a managed database, secured with SSL, deployed from Git, monitored enough to catch obvious failures.
That sentence is boring.
That is the point.
Boring infrastructure is often excellent MVP infrastructure because it leaves your attention for the product, users, pricing, onboarding, positioning, and feedback loops.
The decision framework for choosing your MVP stack
The right MVP stack depends on what you need to prove.
If you are still validating demand, choose the simplest stack that gets the product in front of users. If you already have traction and a team that can manage more operational layers, a managed platform or more modular architecture may make sense. If you are already operating at scale, microservices can become reasonable.
But most MVPs are not there yet.
The table below gives a practical decision framework.
| Stack type | Setup speed | Complexity | Cost | Scalability | Best fit |
|---|---|---|---|---|---|
| Single VM stack | Fast | Low | Low | Moderate | MVPs, early SaaS, founder-led products |
| Managed platform stack | Medium-fast | Medium | Medium | High | Teams with early traction and limited infrastructure appetite |
| Microservices stack | Slow | High | High | Very high | Scale-stage products with multiple engineering teams |
A single VM stack is usually the best choice when speed matters more than distributed architecture. It gives you a clear place to run the app, a simple path to deploy updates, and fewer moving parts to debug.
A managed platform can be useful when your team wants less server ownership and is comfortable paying more for abstraction. It can reduce some operational burden, but it may also hide details that become important when debugging performance, networking, or cost.
A microservices stack should usually wait. It becomes useful when separate teams own separate domains, deployment independence matters, and the product has real operational pressure. Before that, it often creates more coordination cost than value.
Use this rule:
If your product has fewer than 10 active users, fewer than 10 engineers, and no proven traffic bottleneck, microservices are probably premature.
That does not mean microservices are bad. It means timing matters.
Choose a single VM stack if
Choose a single VM stack if you need to launch quickly, keep costs low, and understand the full environment without involving a dedicated infrastructure team.
This is usually the right option when:
- You are pre-product-market fit
- You need to launch in days, not weeks
- The team is small
- One developer should be able to debug the whole system
- You are running a web app, API, dashboard, internal tool, or early SaaS product
- Your current scaling needs are unknown
A single VM does not mean careless infrastructure. It means focused infrastructure.
You can still use version control, SSL, backups, monitoring, Docker, firewalls, and clean deployment practices. The difference is that everything remains understandable.

Choose a managed platform if
Choose a managed platform if you want to avoid server management and are willing to accept more platform constraints.
This can work well when:
- You have early users
- You value convenience over low-level control
- Your team does not want to manage operating system updates
- Your app fits the platform’s deployment model cleanly
- You are comfortable with pricing that may rise as usage grows
Managed platforms can be excellent for some teams. The risk is that they sometimes make the first launch easy but later make cost control, migration, or advanced configuration harder.
For an MVP, that trade-off may still be worth it.
Avoid microservices if
Avoid microservices if the product does not yet have clear service boundaries, multiple engineering teams, or real scaling pain.
Microservices add overhead in several places:
- More repositories or packages
- More deployments
- More internal networking
- More logs
- More secrets
- More failure modes
- More coordination
- More local development complexity
For a mature platform, that overhead may be worth it. For a young MVP, it usually is not.
A distributed system is harder to debug than a simple one. If the product itself is still changing every day, the infrastructure should not be the most rigid part of the company.
Suggested placement: after the decision framework table. This visual reinforces why the single VM stack is usually the best fit for a fast MVP launch.
The core components of a simple MVP stack
A good MVP stack is not random. It is deliberately small.
Each part should have a clear job. If a component does not help the product launch, support users, or reduce real operational risk, it probably does not belong in the first version.
Application compute
The compute layer is where your application runs.
For a 48-hour MVP, a Linux VM is often the most direct option. It gives you a dedicated server environment, full root access, predictable resources, and enough flexibility to run common frameworks, APIs, background workers, reverse proxies, and Docker-based setups.
This is one reason VMs remain underrated for early-stage products. They are easy to reason about.
You know where the app is. You know how to restart it. You know where the logs live. You know what resources are attached to it. You can SSH into the machine, inspect the system, and fix issues directly.
That level of visibility is valuable when speed matters.
A single VM can run:
- A web application
- An API server
- A reverse proxy such as Nginx or Caddy
- Background workers
- Docker Compose
- A small Redis instance
- Lightweight internal tools
- A staging environment
The goal is not to put everything on one machine forever. The goal is to avoid splitting things before splitting solves a real problem.
Database
For most MVPs, the database should be boring and reliable.
PostgreSQL is usually the default choice because it is mature, widely supported, flexible, and familiar to most engineering teams. Whether you use managed PostgreSQL or a carefully maintained database setup, the key principle is the same: do not let database operations become the product.
At the MVP stage, you do not want your best hours going into backup scripts, replication design, database tuning, or emergency maintenance unless your product specifically requires that depth.
A managed database reduces operational burden. It lets the team focus on schema design, data quality, and product behavior instead of database administration.
If managed PostgreSQL is available in your chosen environment, use it. If not, keep the database setup conservative, documented, backed up, and easy to migrate later.
Domain and SSL
A real domain and SSL are not optional for a serious MVP.
They are basic technically, but important psychologically. A real domain makes the product easier to share, easier to test, easier to support, and easier for users to trust.
Early products already ask users to tolerate some rough edges. Do not make the product feel temporary before the user even signs in.
For most MVPs, a simple setup is enough:
- Domain connected to the app
- HTTPS enabled
- Redirects configured correctly
- Basic DNS records documented
- No unnecessary CDN or edge complexity unless the product needs it
A domain and SSL layer gives the product a minimum level of credibility. That matters when asking early users, investors, teammates, or pilot customers to take the product seriously.
Deployment flow
Deployment should be boring.
A simple MVP deployment flow might look like this:
- Code lives in GitHub
- Changes are merged into the main branch
- Basic tests or checks run
- The app builds
- The server pulls or receives the new version
- The process restarts cleanly
- Logs can be reviewed if something breaks
That is enough to start.
You do not need an enterprise CI/CD platform on day one. You need a repeatable deployment flow that the team trusts.
If Docker makes deployment more consistent, use it. If Docker becomes another layer your team has to fight, skip it until it earns its place. The tool is not the point. Reliable shipping is the point.
Monitoring
MVP monitoring should answer simple questions:
- Is the app up?
- Is it responding?
- Is it failing?
- Are CPU, memory, or disk usage becoming dangerous?
- Can someone see logs quickly?
- Will the team know if something important breaks?
That is enough for the first version.
A wall of dashboards does not make an MVP more responsible. Useful visibility does.
Start with uptime checks, basic server metrics, error visibility, and logs that a normal developer can understand. Add deeper observability when the product has enough users or revenue to justify it.
Backups and snapshots
Backups are not advanced infrastructure. They are basic survival.
Even an MVP needs a way to recover from mistakes. Early teams often move quickly, change schemas, run scripts, test migrations, and experiment with product logic. That speed is useful, but it increases the chance of accidental data loss.
A practical MVP backup plan should include:
- Database backups
- VM snapshots before risky changes
- Clear restore expectations
- Basic documentation on where backups live
- Periodic restore testing when the product becomes business-critical
The key is not to build an elaborate disaster recovery system on day one. The key is to avoid having no recovery path at all.
Object storage
Object storage should be added only when the product actually needs it.
If users upload files, images, documents, generated assets, exports, or media, object storage makes sense. If the product does not handle files, adding object storage “just in case” creates another service to configure and monitor.
A useful rule is:
Store application state in the database. Store user files and large static assets in object storage. Do not add object storage until the product has a real file-storage need.
This keeps the initial stack clean while leaving a clear path to expand later.
Best practices for 48-hour MVP infrastructure
The best MVP infrastructure is not the smallest possible stack. It is the smallest responsible stack.
That distinction matters.
A careless stack creates future pain. A disciplined stack avoids unnecessary complexity while still giving the product a stable foundation.
Keep the architecture flat
Keep the application as close together as possible until the product proves why it should be split.
A flat architecture reduces coordination cost. There are fewer network calls, fewer deployment paths, fewer logs, fewer secrets, and fewer places for bugs to hide.
This does not mean writing messy code. You can still structure the application cleanly internally. The point is to avoid operational separation before the business has earned it.
Use tools your team already understands
For a 48-hour MVP, familiarity beats novelty.
If your team knows Laravel, use Laravel. If your team knows Django, use Django. If your team is fastest with Next.js, use Next.js. The framework choice matters less than the team’s ability to build, deploy, debug, and improve the product quickly.
A technically superior tool that slows the team down is usually the wrong MVP choice.
The best stack is often the one your team can operate calmly under pressure.
Make debugging obvious
A good MVP stack should make debugging easy.
When something breaks, the team should know where to look first. That means logs should be accessible, deployment history should be understandable, and the relationship between components should be simple.
If a user reports a problem, you should be able to ask:
- Is the app running?
- Did the last deployment cause this?
- Is the database reachable?
- Are environment variables correct?
- Are errors appearing in logs?
- Is the server under resource pressure?
If answering those questions requires searching across five tools and three services, the stack may be too complex for the stage.
Delay orchestration until it solves a real problem
Kubernetes is powerful, but it is rarely the right first move for a 48-hour MVP.
The problem is not Kubernetes itself. The problem is operational timing.
Kubernetes introduces clusters, manifests, services, ingress, secrets, resource requests, monitoring, deployment strategies, and operational concepts that must be understood and maintained. That investment can be justified when the product needs it. It is much harder to justify before users arrive.
Use orchestration when the product has enough scale, team structure, or reliability requirements to make the overhead worthwhile.
Until then, keep deployment simpler.
Treat infrastructure changes as product decisions
Infrastructure decisions affect product speed.
Every new tool changes how fast the team can deploy, debug, hire, onboard, document, and recover. That means infrastructure decisions should not be made only on technical preference.
Before adding a new component, ask:
- What user problem does this help solve?
- What operational problem does this remove?
- What new maintenance does this introduce?
- Who will own it?
- Can we launch without it?
- Can we add it later without major damage?
If the answer is unclear, wait.
What not to use in the first 48 hours
A good MVP stack is defined as much by what it excludes as what it includes.
The early version should avoid tools that create operational weight before the product proves it needs them.
Do not start with Kubernetes by default
Kubernetes is excellent for certain production workloads, but it is not automatically excellent for MVPs.
At the MVP stage, Kubernetes often adds more decisions than it removes. You need to think about cluster setup, ingress, container registries, secrets, scaling policies, deployment patterns, resource limits, and monitoring before the product has proven demand.
That can be a poor trade.
If your MVP can run on a single VM with a simple deployment process, start there. You can move to orchestration later when the product has earned the shift.
Do not split into microservices too early
Most MVPs do not have a service-boundary problem.
They have a focus problem.
Splitting a young product into services can make the team feel more “scalable,” but it also creates more deployment work, more integration work, and more debugging complexity. Worse, the boundaries are often wrong because the product is still changing.
Good service boundaries emerge from real usage, real domain understanding, and real team ownership.
Guessing them too early usually creates rework.
Do not add tools for imagined future needs
A tool that might be useful later is not automatically useful now.
Object storage, queues, service meshes, distributed tracing, event buses, orchestration, and multiple environments can all be valuable. But each one should earn its place.
At the MVP stage, “we might need this later” is not enough.
The better question is:
Does this help us launch, validate, recover, or serve users right now?
If not, document it as a future option and move on.
When to add more infrastructure
Simple infrastructure does not mean staying simple forever.
Healthy products evolve. They begin with a clear foundation, then add complexity when growth makes the trade worthwhile.
The mistake is not adding complexity. The mistake is adding it before there is evidence.
Add more infrastructure when one of these conditions becomes true:
- Users are growing and performance bottlenecks are measurable
- Deployments are becoming risky or too frequent for the current setup
- The team has grown and ownership boundaries are becoming clearer
- Background jobs need to be separated from request handling
- File storage, caching, queues, or search become core product needs
- Security or compliance requirements demand stronger separation
- Downtime risk becomes more expensive than infrastructure complexity
- The cost of staying simple becomes higher than the cost of evolving
That is what “complexity should be earned” means.
A growing product may eventually need load balancing, separate services, caching, object storage, queues, staging environments, infrastructure as code, or orchestration.
But those should come from pressure, not fear.
Fear says:
We might need this someday, so let’s build it now.
Discipline says:
We know what would trigger this upgrade, and we will add it when that trigger appears.
The second approach is usually healthier.
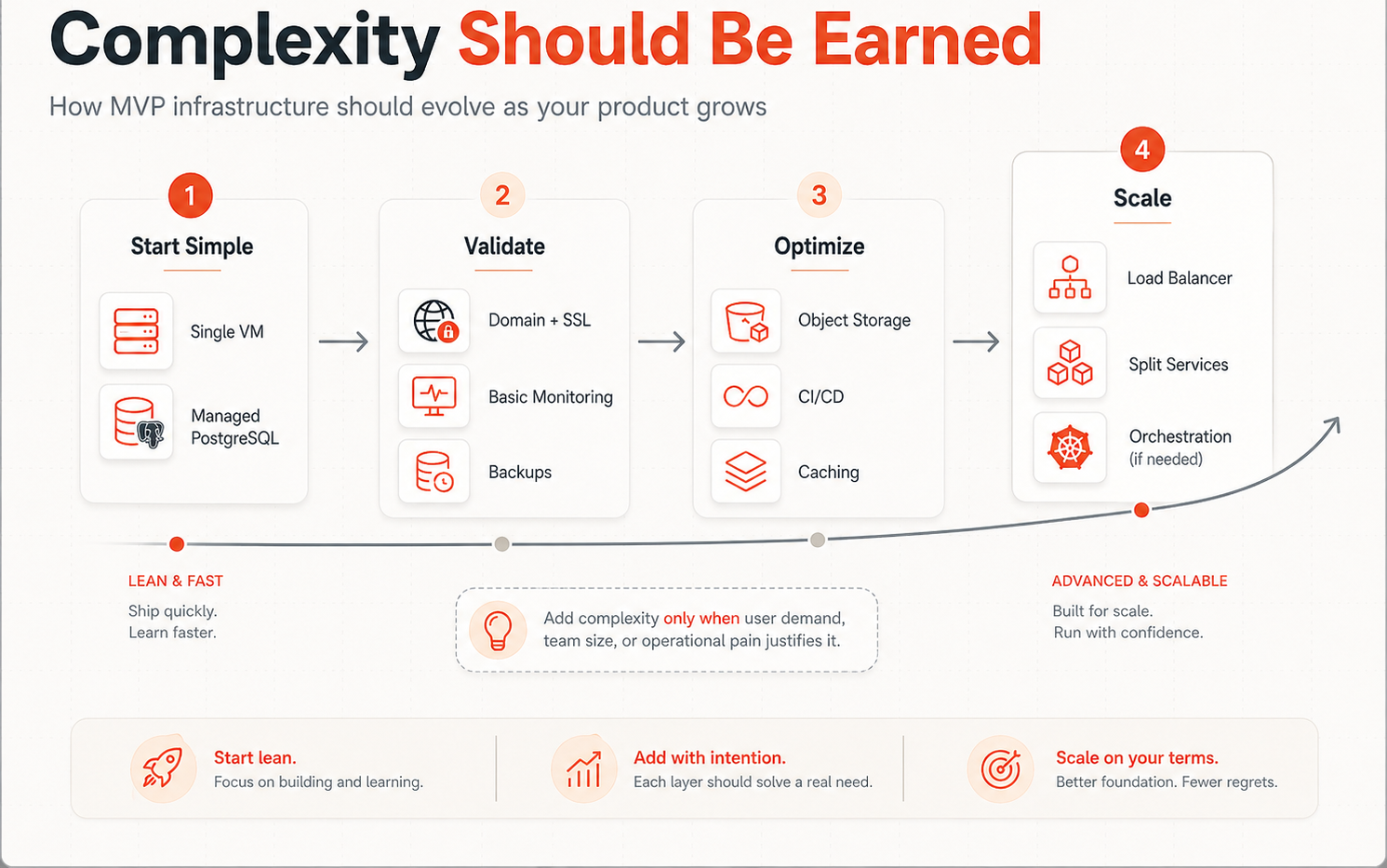
Suggested placement: after the “When to add more infrastructure” section. This visual explains the growth path from simple MVP infrastructure to scalable infrastructure.
How this applies on Raff Technologies
Raff Technologies is designed around a simple idea: cloud infrastructure should be fast, understandable, and reliable without forcing early teams into unnecessary complexity.
That philosophy fits the 48-hour MVP stack well.
For teams building an MVP, a Raff Linux VM gives you a straightforward place to run the first version of the product. You can deploy common Linux distributions, use full root access, connect over SSH, install the runtime your application needs, configure a reverse proxy, and run the app in an environment your team can understand.
Raff Linux VPS plans start at $3.99/month, support 9 Linux distributions, and can be deployed in under 60 seconds. That matters for MVPs because infrastructure setup should not consume the week you planned to spend building and validating the product.
A simple Raff-based MVP stack might look like this:
- Raff Linux VM for the application runtime
- PostgreSQL for relational data
- Domain and SSL for trust
- Basic monitoring for uptime and resource usage
- Snapshots or backups before risky changes
- Object storage only if the product handles files or generated assets
The decision rationale is simple: early teams need infrastructure that preserves momentum.
At Raff, we see that small teams often move faster when they can understand the whole system without waiting on infrastructure specialists. A single VM gives enough control to deploy real software, enough flexibility to evolve, and enough simplicity to keep the team focused on users rather than cloud architecture.
If your decision framework points toward a single VM stack, Raff is a practical place to start because it gives you the core compute layer without forcing a complex platform model on day one.
Common mistakes when building MVP infrastructure
Even simple stacks can become messy if the team does not make deliberate choices.
The most common mistake is treating the MVP as a smaller version of a future enterprise platform. That mindset leads to too many services, too many tools, and too many assumptions before the product has evidence.
Another mistake is ignoring recovery. Some founders hear “simple infrastructure” and interpret it as “no operational discipline.” That is dangerous. Simple infrastructure still needs backups, SSL, access control, and basic monitoring.
A third mistake is spreading the stack across too many providers too early. It can feel flexible, but it often creates more account management, more billing complexity, more networking questions, and more failure points. Early teams usually benefit from fewer surfaces to manage.
The final mistake is optimizing for what looks impressive rather than what ships.
A 48-hour MVP stack should not be judged by how sophisticated the diagram looks. It should be judged by whether the product gets into users’ hands quickly, reliably, and with enough operational clarity to improve it.
Conclusion
A 48-hour MVP stack is not about choosing weak infrastructure. It is about choosing infrastructure that matches the stage of the product.
Before product-market fit, the best infrastructure decision is often the one that helps you launch, learn, and iterate with the least operational drag. For many teams, that means a single VM, a reliable database, SSL, basic monitoring, and a clear recovery path.
You can always add complexity later. In fact, you should — when users, revenue, team size, or operational pressure justify it.
If you are building your first MVP and want a simple place to run it, start with a Raff Linux VM, keep the stack understandable, and add each new layer only when the product earns it.