
Choosing the right VM size means matching CPU, memory, storage, and network capacity to the workload’s actual behavior. The best starting VM is not the largest plan you can afford; it is the smallest plan that can run normal demand reliably, absorb expected peaks, and leave a clear path to resize.
A web application, database, CI runner, container host, and Windows remote desktop server can use the same headline resources very differently. Start by identifying the likely bottleneck, then confirm the decision with monitoring after deployment.
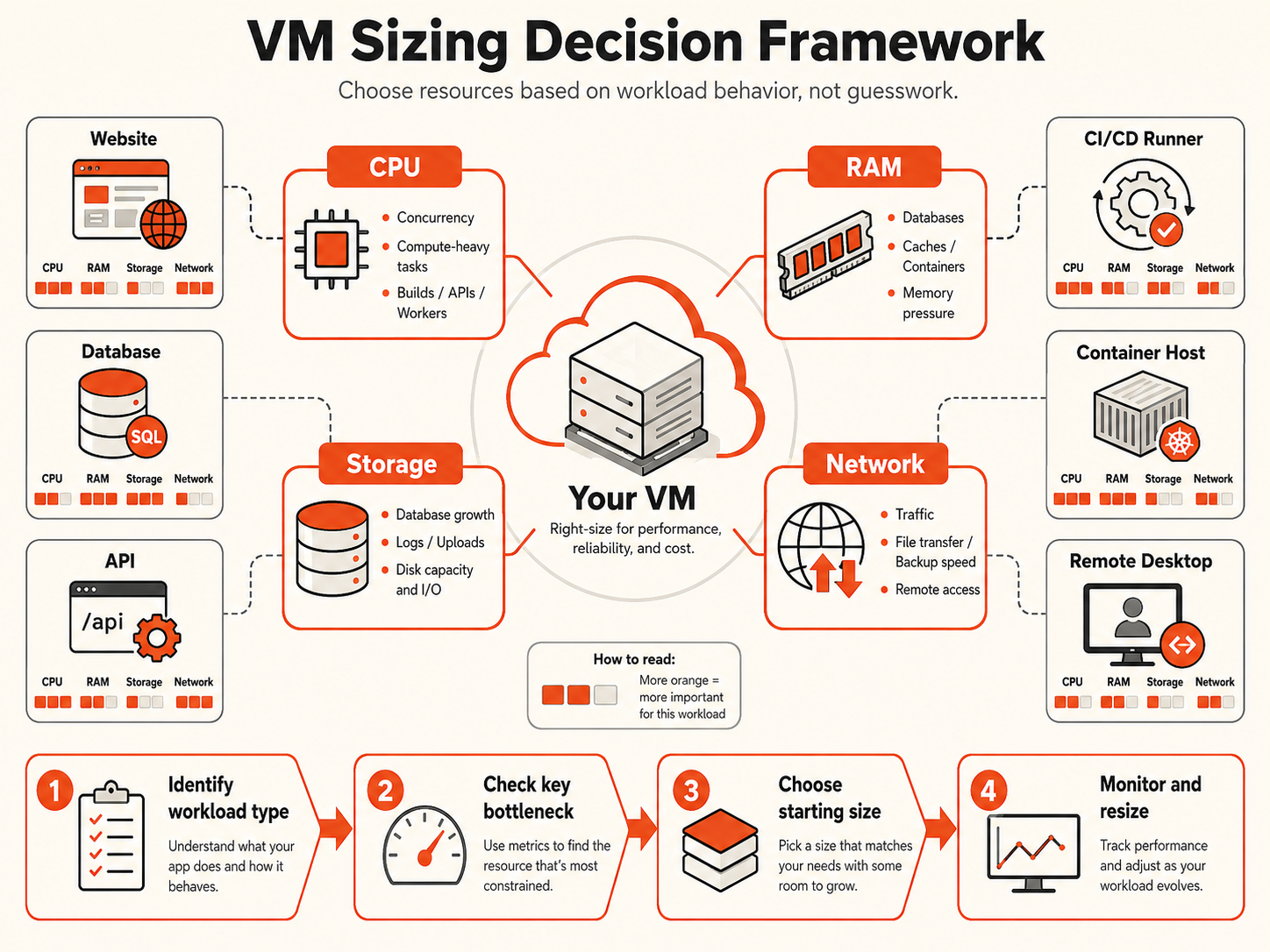
VM sizing starts with workload behavior
Classify the workload before opening a plan table.
Ask:
- Is it production, staging, development, or temporary testing?
- Is demand steady, bursty, scheduled, or unpredictable?
- Does it serve users directly?
- Does it run a database, containers, workers, builds, or remote desktops?
- Which failure hurts first: slow responses, process crashes, full disk, or long job queues?
- Can the workload be resized or separated later?
Sizing fails in two directions. An undersized VM creates latency, swapping, failed jobs, restarts, and operational noise. An oversized VM hides problems but leaves paid capacity idle.
Use evidence where available and conservative assumptions where it is not.
CPU, memory, storage, and network play different roles
CPU controls compute throughput
CPU affects concurrent request handling, build time, background jobs, encryption, compression, query execution, indexing, and media processing.
Likely CPU-bound workloads include:
- CI/CD runners
- queue workers
- compilation and test jobs
- image or video processing
- high-concurrency APIs
- search and indexing
- report generation
Signs of CPU pressure include sustained high utilization, growing work queues, rising response times, and jobs taking longer during otherwise normal demand.
Memory protects stability
RAM is used by the operating system, application runtime, database cache, containers, workers, and monitoring agents.
Signs of memory pressure include:
- swap activity
- out-of-memory events
- process restarts
- database latency
- unstable containers
- application pauses
Databases, JVM applications, search systems, caches, analytics tools, and multi-container hosts often become memory-constrained before they become CPU-constrained.
Storage has capacity and performance dimensions
Storage sizing must cover both how much data exists and how the workload reads or writes it.
Include:
- operating-system files
- application code
- database and index growth
- uploads
- logs
- container images
- temporary files
- build artifacts
- monitoring data
- local backup staging
A full disk can stop database writes, deployments, logging, and package updates. Monitor free space and growth rate rather than treating the initial allocation as permanent.
Network matters for data-moving workloads
Network behavior matters for APIs, file transfer, replication, backups, media delivery, remote desktop, and communication between services.
Consider average and peak throughput, request size, user geography, internal service traffic, and whether transfer is included or metered.
A practical VM sizing framework
Use workload shape rather than universal plan recommendations.
| Workload pattern | First resource to examine | Safer starting direction |
|---|---|---|
| Static site or small proxy | Memory and storage | Small balanced VM |
| CMS or small business site | Memory, storage growth, PHP/runtime workers | Balanced VM with room for plugins and traffic peaks |
| Web app or API | CPU concurrency and memory | Balanced production VM, then monitor latency and saturation |
| Database | Memory, disk latency, working set | Memory-conscious VM with fast storage and backup headroom |
| Container host | Aggregate memory and CPU limits | Balanced VM with reserved OS headroom |
| CI/CD runner | CPU, job parallelism, temporary storage | Compute-oriented VM sized by concurrent jobs |
| Background workers | CPU and queue depth | Scale by measured throughput and backlog |
| Windows remote desktop | Memory per session, CPU responsiveness, storage | Size from active users and application requirements |
| File-heavy service | Storage growth and throughput | VM plus block or object storage where appropriate |
These are decision directions, not guarantees. Framework overhead, traffic, code quality, database design, and user behavior can move the correct size significantly.
General Purpose vs CPU-Optimized
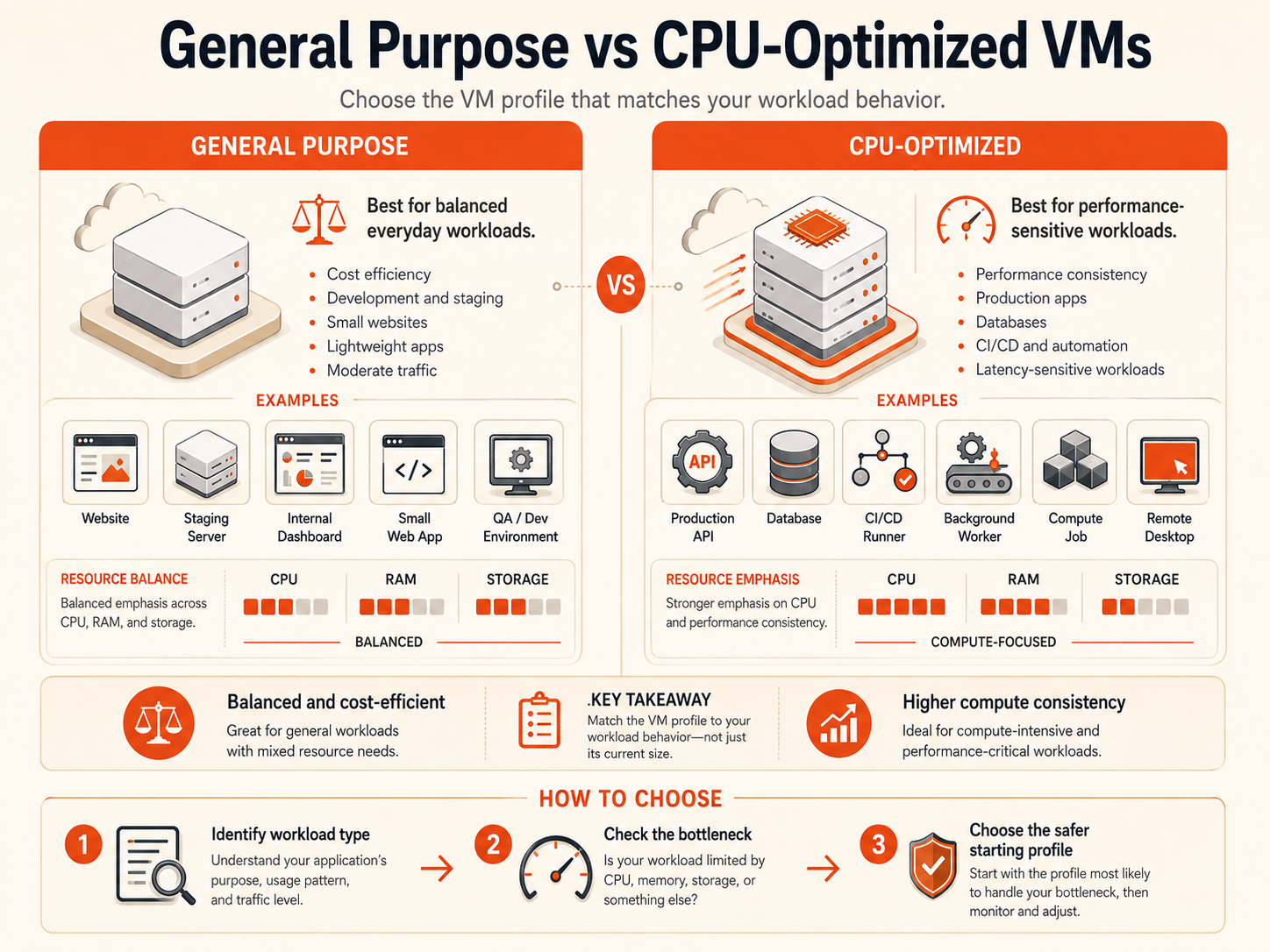
General Purpose VMs fit workloads with relatively balanced CPU and memory needs, such as development environments, staging servers, small websites, internal tools, and moderate application traffic.
CPU-Optimized VMs fit workloads where sustained compute performance affects users, job completion, or revenue, such as build runners, workers, processing jobs, production APIs, and selected database workloads.
Choose based on measured behavior:
- Prefer General Purpose when the workload is balanced and occasional CPU variation is acceptable.
- Prefer CPU-Optimized when sustained compute demand or latency sensitivity is the main constraint.
- Add memory when swapping, cache pressure, or out-of-memory events are the real problem.
- Change architecture when one VM is no longer the right boundary.
Databases need separate sizing logic
A database should be sized from its working set, connection count, query behavior, write rate, index size, storage growth, and recovery process.
Review:
- database and index size
- active and peak connections
- buffer/cache behavior
- slow queries
- read/write ratio
- disk latency and throughput
- backup duration and restore needs
- replication requirements
Adding CPU will not fix every database issue. Poor queries, missing indexes, lock contention, insufficient memory, or slow storage may be the actual bottleneck.
A small application can begin with the database on the same VM. Separate it when resource contention, recovery requirements, access control, or independent scaling justify the extra service boundary.
Containers require host-level headroom
A container host must support the combined demand of every container plus the operating system and platform agents.
Account for:
- container memory limits
- CPU bursts
- image storage
- log growth
- database or cache containers
- restart behavior
- background jobs
- monitoring agents
Set resource limits where appropriate and monitor the host as well as individual containers. One unbounded container can degrade every service on the VM.
Production and staging should not use identical logic
Production sizing prioritizes user impact, recovery, and peak behavior. Staging sizing depends on its purpose.
- Functional staging can usually be smaller.
- Performance staging should resemble production closely enough to produce useful results.
- CI and load-test environments may need high temporary compute despite low normal usage.
- Preview environments should have ownership and expiry rules so they do not become permanent idle cost.
Do not shrink staging so far that it creates failures that would not occur in production, and do not copy production capacity when the environment only needs functional validation.
How to recognize an undersized VM
A VM may be too small when normal demand causes:
- sustained CPU saturation
- growing queue depth
- high swap usage
- out-of-memory events
- process restarts
- slow database queries
- disk latency
- critically low free space
- rising response time
- failed builds or deployments
Resize according to the bottleneck. More CPU does not fix memory pressure; more RAM does not fix a full disk; a larger VM does not fix an inefficient query or memory leak.
How to recognize an oversized VM
A VM may be oversized when peak—not only average—usage remains far below available capacity for a meaningful period.
Review:
- peak CPU rather than daily averages
- actual memory working set
- storage growth rate
- seasonal or campaign-driven demand
- scheduled jobs
- required failover headroom
Downsize gradually and keep rollback capacity. Cost optimization should not remove the margin needed during ordinary peaks or maintenance.
A safe right-sizing process
- Classify the workload and its business importance.
- Estimate CPU, memory, storage, and network demand.
- Choose the smallest safe starting profile.
- Define which metrics will validate the choice.
- Deploy and observe normal and peak behavior.
- Identify the real bottleneck before resizing.
- Resize upward or downward based on evidence.
- Recheck after releases, campaigns, migrations, and database growth.
- Separate services when independent scaling or recovery becomes valuable.
- Review cost and utilization regularly.
Do not wait for an outage before collecting metrics. CPU, memory, disk usage, disk latency, network throughput, application latency, error rate, and queue depth provide different parts of the sizing picture.
How this applies on Raff
Raff Cloud Servers provide General Purpose and CPU-Optimized profiles with NVMe storage, unmetered server bandwidth, private networking, monitoring, and a resize path through the dashboard.
A practical Raff approach is:
- Use General Purpose for balanced websites, internal tools, development, and normal staging.
- Use CPU-Optimized when sustained compute or latency sensitivity is the main concern.
- Use Volumes when persistent storage growth should be separated from the boot disk.
- Use Object Storage for compatible uploads, archives, and backup objects.
- Separate databases or workers when one VM creates resource contention or recovery coupling.
- Verify current plan resources and prices on the live pricing page.
Do not build an evergreen sizing guide around one historical starting price. Product plans can change; workload behavior is the durable decision input.
VM sizing checklist
Before choosing or resizing a VM, confirm:
- Workload type and environment
- Normal and peak traffic
- CPU-intensive tasks
- Memory-intensive services
- Database size and connections
- Container count and limits
- Storage growth and log retention
- Backup and restore impact
- Network and transfer needs
- Monitoring metrics
- Resize and rollback path
- Next review date