Single VM vs multi-VM architecture is the decision of whether your SaaS app should run all production roles on one server or split the application, database, workers, cache, storage, and traffic routing across separate infrastructure.
For Raff Technologies users, this decision usually appears when an early SaaS product moves from "it works" to "customers depend on it." A single VM is the fastest way to launch. Multi-VM architecture becomes useful when reliability, recovery, scaling, or operational clarity matters more than keeping everything on one machine.
The practical answer is simple: start with one VM when speed and simplicity matter, then split roles only when each split reduces a real production risk. This guide explains when a single VM is enough, when multi-VM architecture becomes necessary, which role to split first, and how to build a staged Raff path without overbuilding like a large cloud team.
For launch readiness before this decision, read the Production VPS Checklist Before Launching a SaaS App. For the first split, read Separate App and Database Server.
SaaS architecture usually starts on one VM
A single VM is often the best starting point for a young SaaS app because it keeps deployment, debugging, networking, and cost simple.
When your product is still validating users, pricing, onboarding, and core workflows, infrastructure complexity can become a distraction. The biggest early risk is usually not that your architecture is too small. The bigger risk is spending engineering time on production topology before the product has enough usage to justify it.
A single Raff Linux VM can run a web app, API, reverse proxy, database, background worker, cache, scheduled jobs, and monitoring for many early products. That does not mean it is the final architecture. It means one VM gives you a clear baseline before adding moving parts.
A typical early SaaS VM might include:
- Nginx or Caddy as a reverse proxy
- Node.js, Python, Ruby, PHP, Go, or Java application runtime
- PostgreSQL, MySQL, MariaDB, or SQLite for data
- Redis for cache or queues
- Background workers
- Cron jobs or scheduled tasks
- Application logs
- Monitoring agent
- Firewall rules
- SSL/TLS certificates
- Temporary upload or processing folders
This setup is not wrong. It is a normal starting point. The danger appears when the same VM remains responsible for everything after the product has grown beyond that model.
One VM is attractive because it keeps the team focused
A single VM gives small teams four important advantages: low cost, low mental overhead, fast iteration, and fewer deployment dependencies.
You do not need to design private networking, service discovery, load balancer health checks, database connection routing, multi-server logging, or separate deployment pipelines on day one. You can SSH into one machine, inspect logs, restart services, and understand the whole system.
From a founder's point of view, that matters. A simple architecture keeps the team focused on customer feedback instead of infrastructure diagrams.
One VM is especially reasonable for:
- Prototypes
- Demos
- Internal tools
- Staging environments
- Early MVPs
- Low-traffic SaaS products
- Apps with small databases
- Apps where uploads are temporary or low-risk
- Teams that still need to validate demand
The mistake is not starting simple. The mistake is staying simple after the system starts showing production risk.
A good single-VM setup should still have a defined exit point. Before launch, decide what signals will force the next step: database pressure, worker load, disk growth, restore risk, uptime expectations, or multi-server traffic.
Single VM architecture breaks when roles compete
Single VM architecture starts to break when different workloads compete for the same CPU, RAM, disk, network, or maintenance window.
The VM may still be running, but the architecture becomes harder to operate safely. The problem is not only performance. It is blast radius.
If the database consumes disk, the application can fail. If background jobs spike CPU, user requests slow down. If logs or uploads fill the same disk as the database, recovery becomes harder. If a deployment restarts the wrong process, web traffic and workers can both be affected.
A single VM turns many failure modes into one shared failure domain.
You should consider moving beyond one VM when you see patterns like these:
- Web requests slow down during background jobs
- Database CPU or disk I/O affects the application
- Deployments require full-server downtime
- The database and app compete for memory
- Cache growth threatens the database or app process
- Backups slow down the production server
- Log files or uploads fill the same disk as the database
- One restart affects too many services
- You cannot scale one role without scaling everything
- Debugging incidents becomes confusing because all roles share the same host
- A restore would bring back too much unrelated state at once
- Adding a second app server is blocked by local uploads or local sessions
One warning sign does not always mean you need a full multi-VM architecture. Repeated resource contention is a signal that at least one role should be separated.
Operational confusion is the hidden cost of one VM
The hardest part of single VM architecture is not the first install. It is knowing what changed when something goes wrong.
If web traffic spikes, background workers retry failed jobs, Redis memory grows, PostgreSQL writes more data, logs rotate badly, and uploads grow at the same time, one VM makes it harder to isolate the root cause. Everything is sharing the same system metrics.
When separate roles live on separate VMs or managed services, the architecture becomes easier to reason about.
If the worker VM is overloaded, you know the app VM and database are separate concerns. If database latency rises, you can investigate queries and connections without guessing whether the web server is also causing pressure. If the app VM needs replacement, you do not have to move uploaded files or database state at the same time.
That separation improves incident response even before it improves raw performance.
For many SaaS teams, this is the real reason to split: the system becomes easier to operate under pressure.
Multi-VM architecture does not mean microservices
Multi-VM architecture does not mean microservices. It does not mean Kubernetes. It does not mean a large engineering team.
It simply means separating infrastructure roles across multiple virtual machines or managed services.
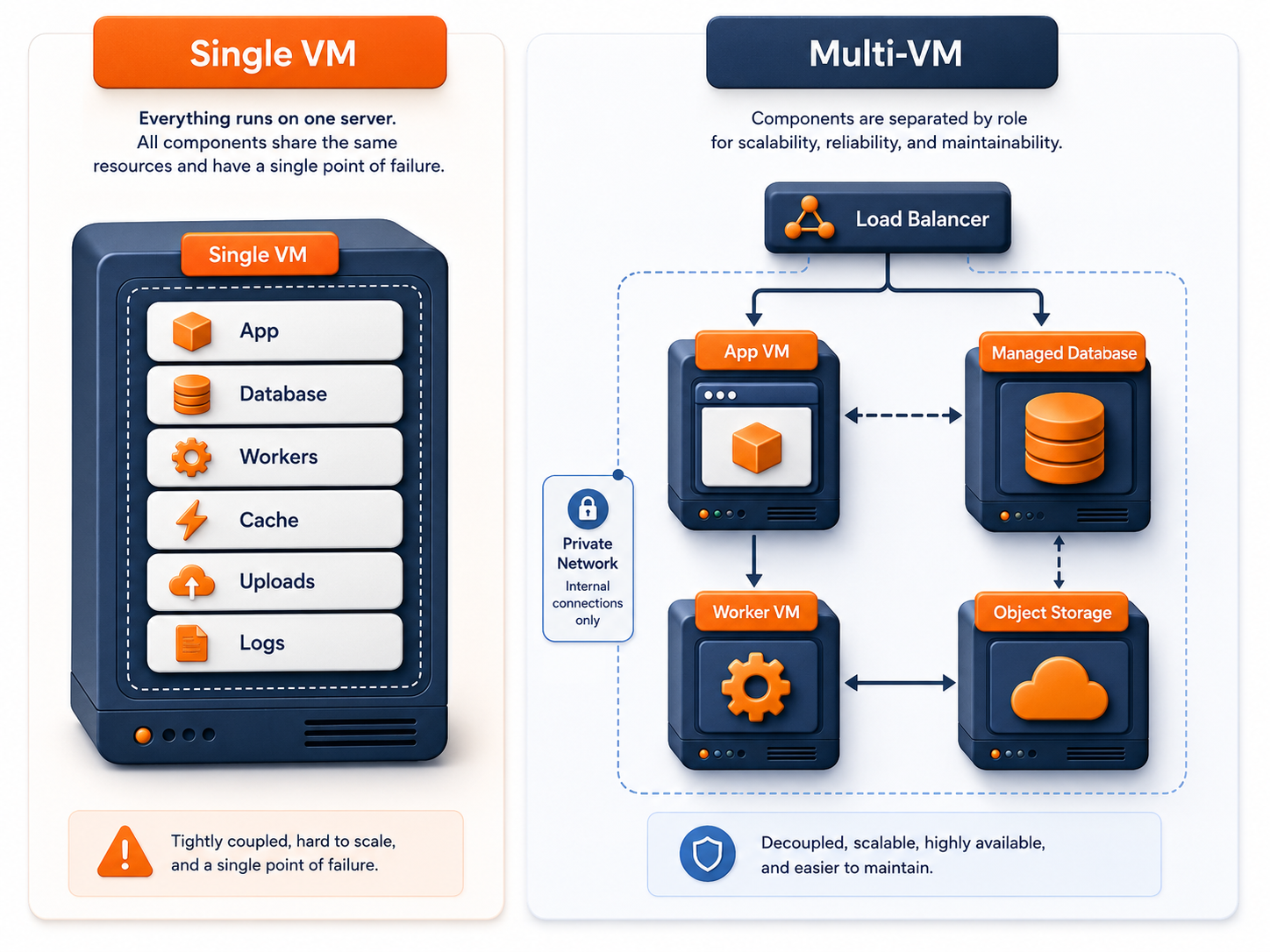
A SaaS app can remain a monolith while running on multiple VMs. For many small teams, that is the ideal middle ground: keep the application code simple, but split infrastructure roles where reliability and scaling require it.
A practical multi-VM SaaS architecture might look like this:
| Role | VM or service | Purpose |
|---|
| Load balancer | Raff Load Balancer | Routes traffic across app servers |
| App server | Raff Linux VM | Runs the web app or API |
| Database | Raff Managed Database or database VM | Stores persistent application data |
| Worker | Raff Linux VM | Handles queues, emails, reports, imports, and scheduled jobs |
| Cache / queue | Redis VM or managed service | Handles cache, sessions, queues, or temporary application state |
| Object storage | Raff Object Storage | Stores user uploads, exports, media, reports, and backup archives |
| Private network | Raff private networking | Keeps internal service traffic away from public exposure |
The key is not to split everything at once. The key is to split the role that creates the most risk or bottleneck.
The quick decision framework
Use this table to decide whether to stay on one VM or move to a multi-VM pattern.
| Question | Stay single VM if | Move multi-VM if |
|---|
| Product stage | You are validating the product | You have active users and revenue risk |
| Traffic | Usage is low or predictable | Traffic spikes affect performance |
| Database | Data size and load are small | Database load competes with app traffic |
| Workers | Jobs are light or rare | Jobs delay web requests or spike CPU |
| Cache | Cache is optional | Cache or queue is critical |
| Uploads | Files are temporary or low-risk | Files are part of the product |
| Backups | Restore is simple and tested | Backup size or restore time is increasing |
| Deployments | Restarting one server is acceptable | App and worker deploys need separation |
| Reliability | Downtime is tolerable | Downtime affects customers or revenue |
| Security | One server boundary is acceptable | Internal roles need private access boundaries |
| Team capacity | You need minimum DevOps work | You can monitor and operate multiple roles |
| Cost | Lowest monthly cost matters most | Reliability and isolation justify added cost |
The strongest architecture is not the one with the most servers. It is the one where each added server has a clear purpose.
The first split is usually the database
For most SaaS products, the database is the first role worth separating.
Persistent data is harder to replace than application compute. You can redeploy application code. You can rebuild containers. You can recreate a reverse proxy. You cannot casually recreate customer accounts, billing records, project data, messages, orders, audit history, or uploaded-file metadata.
When the database runs on the same VM as the app, every application deployment, system update, disk issue, backup job, or resource spike can affect the data layer.
Moving the database away from the app server creates a cleaner boundary:
Users
↓
App VM
↓ private network
Database VM or managed database
Database separation gives you:
- Better protection for persistent data
- Independent database backups
- Cleaner application deployments
- Easier app VM replacement
- Less resource competition
- A clearer recovery plan
- Better scaling options later
- Stronger access-control boundaries
- More useful database monitoring
This does not always require self-managing another database VM. A managed database is often the better production choice because it reduces backup, patching, monitoring, and recovery work.
Use Raff Managed Databases when you want PostgreSQL, MySQL, or Redis without operating the database host yourself. Use a separate Raff VM when you need full database control, custom extensions, or host-level tuning.
For the deeper decision, read Managed vs Self-Hosted Databases and Separate App and Database Server.
The second split is often background workers
Background workers are the second role many SaaS teams should separate.
Workers process jobs that do not need to happen inside a user request: sending emails, generating reports, processing uploads, syncing integrations, billing tasks, AI jobs, image resizing, video processing, imports, exports, or scheduled data cleanup.
Workers behave differently from web traffic. They can spike CPU, use more memory, retry failures aggressively, and create heavy database load. If they run on the same VM as the web app, users can feel the impact.
A separate worker VM lets you scale job processing without scaling the web app. It also lets you pause, restart, or deploy workers without interrupting user-facing requests.
Move workers to a separate VM when:
- Jobs delay user-facing requests
- Queue processing creates CPU spikes
- Email, billing, imports, or exports run slowly
- Failed jobs retry aggressively
- Workers need different packages or runtime settings
- You want different deployment timing for workers and web
- You need to scale job capacity separately from web traffic
- Upload processing affects app response time
- Report generation competes with API traffic
This is often the point where a SaaS app starts feeling more mature without becoming overly complex.
The codebase can still be a monolith. The worker can run the same application code with a different command. The infrastructure role is separated even if the application design stays simple.
Uploads should move before app servers multiply
User uploads are one of the most common reasons a SaaS app gets stuck on one server.
If uploads live on the app VM disk, adding a second app VM becomes harder. One server has the file and the other does not. Load balancing can send users to an app instance that cannot find the upload. Backups grow with every file. VM rebuilds become risky because user files are mixed with app runtime state.
A cleaner production pattern is:
App VM
↓
Database stores upload metadata
↓
Object storage stores uploaded files
Use VM disk for temporary upload staging, short-lived processing, cache, and local working files. Use object storage for durable user files: profile images, PDF documents, reports, exports, media, attachments, and generated assets.
Raff Object Storage starts at $7.00/month for the first 100 GB and is S3-compatible at s3.raffusercloud.com.
This lets teams separate file growth from compute growth. The app VM can be resized, rebuilt, replaced, or duplicated without moving every uploaded file.
For the full upload decision, read App Uploads: VM Disk vs Object Storage for SaaS Teams. For the broader storage model, read Object Storage vs Block Storage vs VM Disk.
Cache and queue isolation comes later
A cache or queue becomes worth separating when it becomes important to performance or reliability.
Redis is a common example because it may handle sessions, cache, rate limits, job queues, locks, or temporary application state. If Redis is only used as a small convenience cache, running it on the app VM may be acceptable early. If Redis becomes part of the critical request path or job system, it deserves separate attention.
Cache and queue failures can create strange application behavior:
- Sessions disappear
- Queues stop moving
- Rate limits fail
- Background jobs pile up
- Locks behave unexpectedly
- Cached data grows without clear ownership
- Web requests become slower when Redis is overloaded
Cache separation is useful, but it can also be premature. If your app has low traffic and Redis is lightly used, the added networking and monitoring may not be worth it yet.
A good rule: split cache when its failure would noticeably affect users or when its resource usage starts competing with the application or database.
Multiple app VMs require stateless app design
Adding multiple app VMs behind a load balancer is the classic move from vertical scaling to horizontal scaling.
Instead of making one app server larger, you run two or more app servers and distribute traffic between them:
Users
↓
Load balancer
↓
App VM 1 + App VM 2
↓
Database / cache / object storage
This improves capacity and can improve availability, but only if the application is ready for it.
Before adding multiple app VMs, make sure:
- Sessions are stored in a shared system or secure client-side tokens
- User uploads are stored outside the app VM
- Environment variables are consistent
- Deployments can update app VMs safely
- Health checks can detect broken instances
- The database can handle more app connections
- Logs and metrics can be reviewed across servers
- Background workers do not run accidentally on every app VM
- Cron jobs do not duplicate unless that is intended
- Secrets and configuration are managed consistently
A load balancer helps when one server is not enough, but it does not fix stateful application design by itself.
If the app depends on local uploads, local sessions, or server-specific state, fix that before adding multiple app VMs.
Cost should be compared by role, not server count
A multi-VM architecture increases visible infrastructure cost, but it can reduce operational risk and performance waste.
The right comparison is not:
One server bill vs three server bills.
The better comparison is:
What does each topology cost when performance, downtime, maintenance, recovery, and team time are included?
A single large VM can become expensive if you scale the whole machine because one role needs more resources. If only background workers need more CPU, scaling the app, database, and workers together may waste money. A separate worker VM lets you add capacity only where needed.
Raff's CPU-Optimized 2 vCPU / 4 GB VM costs $19.99/month with 80 GB NVMe SSD and unmetered VM traffic.
That makes it practical for small teams to split roles gradually instead of jumping directly into complex infrastructure. A team might run an app VM, then add a managed database, then add a worker VM only when job load demands it.
A practical cost progression looks like this:
| Stage | Topology | Why it fits |
|---|
| Prototype | One VM | Lowest complexity and fastest iteration |
| Early production | App VM + managed database | Better data protection without too much complexity |
| Growing usage | App VM + database + worker VM | Background jobs stop competing with web traffic |
| Scaling app | Load balancer + 2 app VMs + database + worker | More capacity and better app availability |
| Mature SaaS | Multiple app VMs + workers + cache + private networking | Better isolation, scaling, and operational clarity |
This progression keeps infrastructure aligned with the business instead of forcing enterprise architecture on a young product.
For exact planning, compare VM, managed database, object storage, snapshot, and backup costs on Raff pricing.
A simple Raff production path for SaaS teams
On Raff, a sensible SaaS scaling path is staged.
You do not need to jump from one VM to Kubernetes. You can separate the roles that matter first.
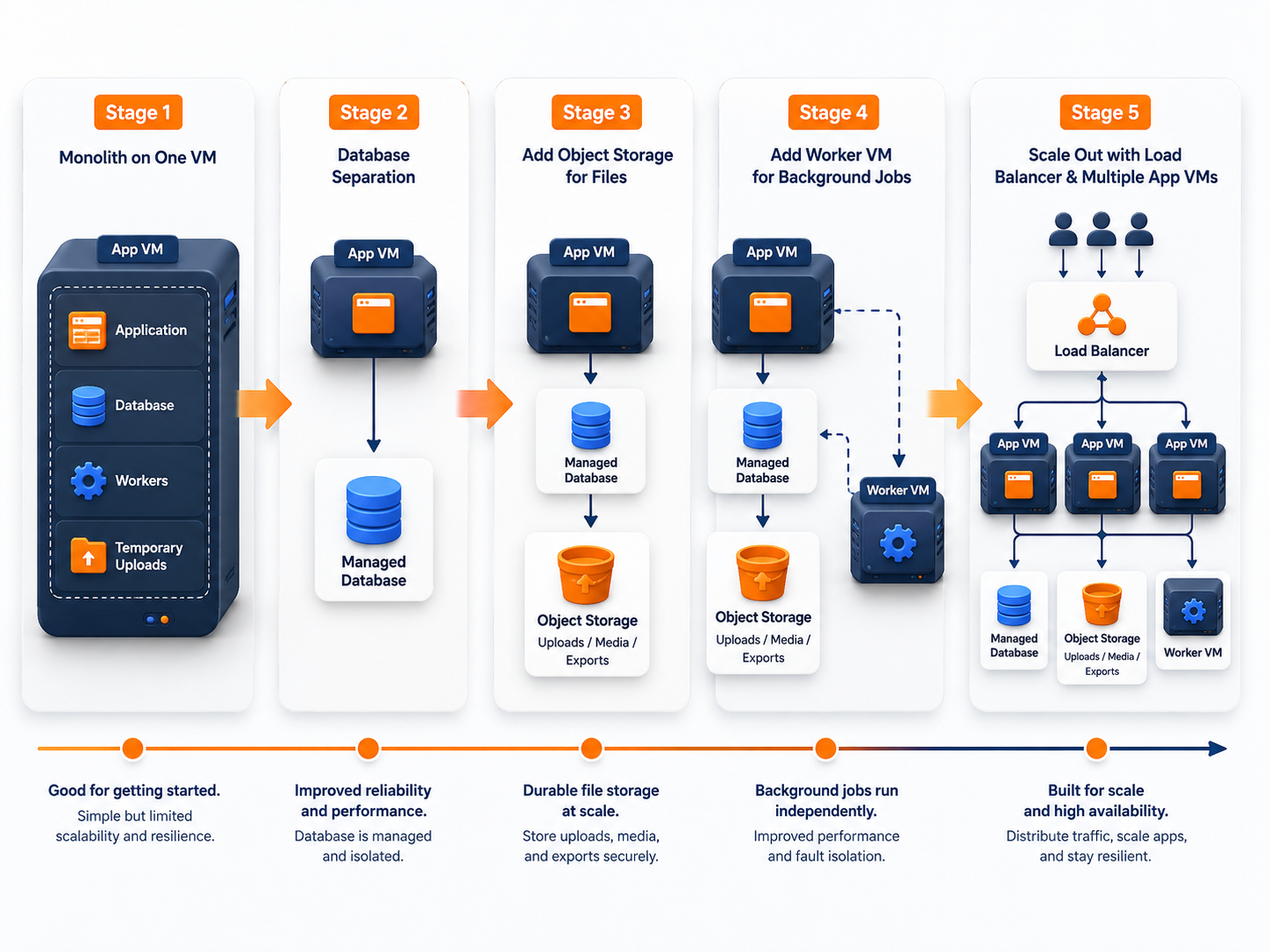
Stage 1: One Raff VM
Start with one Raff VM or Linux VM.
Raff VM
↓
App + database + workers + cache + temporary uploads
This is good for:
- Prototypes
- Internal tools
- Early MVPs
- Low-traffic SaaS apps
- Products still validating demand
The priority is launch speed, basic monitoring, firewall rules, backups, and a clear exit point.
Stage 2: Raff VM + managed database
Move the database out when production data matters.
Raff VM for app
↓ private access
Raff Managed Database
This is good for:
- Production SaaS apps
- Customer data
- Teams without database operators
- Cleaner backups and recovery
- App VM replacement without moving database state
This is usually the first serious production split.
Stage 3: App VM + database + object storage
Move user uploads and generated files out of the app VM.
Raff VM for app
↓
Raff Managed Database for metadata
↓
Raff Object Storage for uploads
This is good for:
- SaaS apps with file uploads
- Reports and exports
- Media-heavy features
- Multi-app-server preparation
- Smaller VM backup and restore scope
This keeps compute, structured data, and file objects in separate layers.
Stage 4: Add worker VMs
Move background jobs away from web traffic.
Load balancer or users
↓
App VM
↓
Database + object storage
↓
Worker VM for jobs
This is good for:
- Email jobs
- Billing jobs
- Report generation
- Imports and exports
- Upload processing
- Scheduled tasks
This split improves user-facing performance without changing the whole application model.
Stage 5: Add load balancing and more app VMs
Add multiple app VMs only when traffic, uptime, or deployment needs justify it.
Users
↓
Raff Load Balancer
↓
App VM 1 + App VM 2
↓
Managed Database + Object Storage + Worker VM
This is good for:
- Higher traffic
- Rolling deployments
- Better app-layer availability
- Separating public entry points from internal roles
At this stage, private networking, health checks, logging, monitoring, and configuration consistency matter much more.
Private networking matters once roles are separated
Private networking becomes important once the architecture spans multiple VMs or services.
App-to-database, app-to-cache, and app-to-worker communication should not rely on public exposure when private traffic is available. Use public access for user-facing entry points and private access for internal service communication.
A safer pattern is:
Public internet
↓
Load balancer or app VM
↓ private network
Database, cache, workers, internal services
The database should not be publicly exposed by default. Workers should not need public ports. Cache systems should not accept traffic from the internet. Internal service communication should be deliberately restricted.
Private networking does not replace application security, database permissions, secret management, or firewall rules. It gives the infrastructure a cleaner boundary.
For database-specific boundaries, read Separate App and Database Server.
Best practices for splitting SaaS roles
Split roles gradually. Do not redesign the whole platform in one move unless you have a strong reason.
1. Measure before splitting
Use CPU, RAM, disk I/O, database load, request latency, error rates, queue depth, and backup duration to identify the real bottleneck.
Guessing creates architecture that looks professional but solves the wrong problem.
2. Split the database before the app layer
Persistent data is the hardest part to recover. Give the database its own environment before adding multiple app servers.
For self-hosted database operations, use a dedicated VM and documented backup plan. For less operational burden, use a managed database.
3. Keep the app server replaceable
If you want multiple app VMs later, avoid storing sessions, uploads, or durable state only on local disk.
The app VM should run the application. It should not be the only home for customer files, production records, or long-term assets.
4. Separate workers when jobs affect users
If background jobs slow the web app, move them to a worker VM.
This is one of the highest-impact splits for growing SaaS apps because it protects user-facing traffic without forcing microservices.
5. Use object storage for durable files
Do not let app uploads block multi-VM scaling.
Store upload metadata in the database and store file bodies in object storage when files matter to users.
6. Use private networking for internal traffic
Database, cache, worker, and internal service communication should use private networks where possible.
Public exposure should be limited to the load balancer or application entry point.
7. Avoid premature microservices
A monolith can run across multiple VMs.
You can split infrastructure roles without splitting the codebase into many services. For small teams, that is often the right balance.
8. Keep backup and restore tied to each role
The app VM, database, object storage, and worker environment do not all need the same backup strategy.
Database recovery is different from file retention. App server snapshots are different from database backups. Upload storage is different from local runtime state.
Use Database Backup Strategy for SaaS Apps once that guide is available, and use Cloud Server Backup Strategy for server-level planning.
The pre-split checklist
Before moving from one VM to multiple roles, review this checklist.
If you cannot explain what risk the new VM reduces, the split may be premature.
Common mistakes to avoid
Splitting everything at once
Moving database, workers, cache, uploads, and load balancing in one project increases migration risk.
Split the role that creates the most pressure first. For most SaaS apps, that is the database or workers.
Adding a load balancer before removing local state
Multiple app VMs are hard when uploads, sessions, or scheduled jobs depend on one server.
Remove local state dependencies before horizontal scaling.
Treating multi-VM as high availability
More VMs do not automatically create high availability.
A separate database VM reduces resource contention, but it does not automatically provide failover. A second app VM helps only if health checks, deployment, state, and routing are designed correctly.
Moving files to the database
A database should usually store upload metadata, not large file bodies.
Use object storage for durable uploads, exports, media, and reports.
Overbuilding before product-market signals
A young SaaS product does not need a large architecture just because larger companies use one.
Start with the simplest production-safe design, then split roles when usage proves the need.
Ignoring monitoring after splitting
A split architecture without monitoring creates more moving parts without better visibility.
Each role should have basic health, resource, and error visibility.
Single VM vs multi-VM architecture comes down to risk
Single VM architecture is the right starting point for many SaaS apps because it is simple, affordable, and easy to operate.
Multi-VM architecture becomes useful when different roles need separate scaling, failure isolation, recovery plans, or maintenance windows. The move should be gradual: start with one Raff VM, separate the database when production data matters, move uploads to object storage when files matter, move workers when background jobs compete with web traffic, and add load balancing when one app server is no longer enough.
This is the production path that keeps Raff infrastructure simple without trapping the team inside a fragile single-server setup.
Next, read Production VPS Checklist Before Launching a SaaS App, Separate App and Database Server, and App Uploads: VM Disk vs Object Storage.
Then compare Raff VM, Raff Managed Databases, Raff Object Storage, and Raff pricing to choose the next role your SaaS app should split.
