
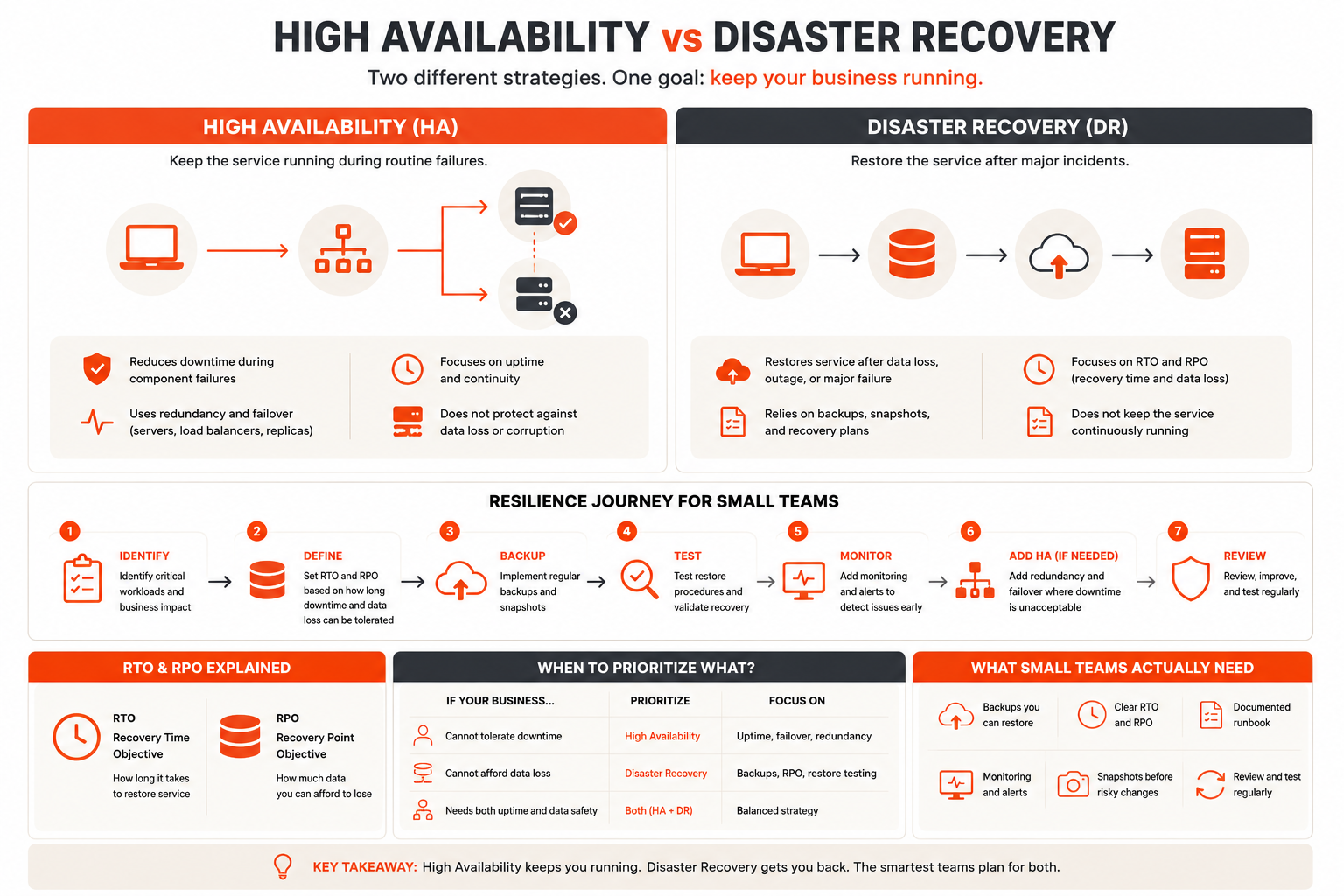
High availability is a design approach that keeps a service running during routine failures, while disaster recovery restores service after larger incidents.
For small teams and SMBs, the difference matters because uptime and recovery are not the same purchase. A business website, customer portal, Windows remote desktop, database, internal dashboard, or office-server replacement workload may need protection, but not every workload needs expensive high-availability architecture on day one. Raff Technologies has deployed 10,000+ VMs for 3,000+ customers, and the most practical resilience plans usually start by asking what the business must keep running and what it must be able to restore.
This guide supports Raff’s Cloud Servers for Small Business cluster. It explains how high availability and disaster recovery differ, how RTO and RPO make the decision practical, and how small teams can protect workloads without overbuilding infrastructure.
High Availability and Disaster Recovery Solve Different Problems
High availability and disaster recovery often appear together because both deal with outages. That overlap creates confusion.
High availability, usually shortened to HA, focuses on keeping a service available when a routine component fails. If one server, process, load balancer, or node fails, another path keeps the service running with little or no interruption.
Disaster recovery, usually shortened to DR, focuses on restoring service after a larger failure. That failure may involve data loss, a bad deployment, provider outage, corrupted database, security incident, accidental deletion, or a broken environment that must be rebuilt.
The difference is easier to see through business impact:
| Failure question | High availability answer | Disaster recovery answer |
|---|---|---|
| Can the service keep running if one component fails? | Yes, if HA is designed correctly | Not the main goal |
| Can the service be restored after a serious incident? | Not enough by itself | Yes, if backups and recovery plans work |
| Does it reduce downtime during routine failure? | Yes | Sometimes, but usually with recovery time |
| Does it protect against data loss? | Not by itself | Yes, if backup and restore design is strong |
| Does it require extra live infrastructure? | Usually yes | Not always |
| Does it require restore testing? | Useful, but not the core control | Essential |
The key point is simple: high availability protects continuity, while disaster recovery protects recoverability.
A small team can have disaster recovery without full high availability. It can also have high availability without good disaster recovery, which is dangerous. A highly available system can still replicate bad data, delete files across nodes, or fail in a way that requires backups.
That is why HA and DR should not be treated as interchangeable.
The Small-Team Resilience Decision Framework
Before buying more infrastructure, define what the workload actually needs.
Use this framework:
| Workload type | Availability need | Recovery need | Practical starting point |
|---|---|---|---|
| Personal project or test VM | Low | Low | Basic backup or rebuild plan |
| Simple marketing website | Medium | Medium | Backups, DNS access, documented restore |
| Internal dashboard | Medium | Medium | Daily backup and clear owner |
| Business website | Medium to high | High | Backups, monitoring, tested restore |
| Customer portal | High | High | Monitoring, backups, restore testing, possible HA |
| Windows remote desktop | Medium to high | High | Backups, access control, restore plan |
| Production database | High | Very high | Frequent backups, restore testing, possible replication |
| Revenue-critical SaaS app | Very high | Very high | HA plus DR planning |
| Office-server replacement workload | Depends on use | High | Recovery-first, then HA for critical services |
 A useful rule for SMBs is this:
A useful rule for SMBs is this:
If downtime is painful but data loss would be worse, start with disaster recovery. If even short downtime stops revenue, customer access, or staff work, evaluate high availability earlier.
This rule prevents overbuilding. Many small teams do not need multi-node HA before they have tested backups. But they do need to know how they would restore the workload if the server, database, or application failed.
The right order is usually:
- Identify the workload.
- Define business impact.
- Set RTO and RPO.
- Build backups and restore process.
- Add monitoring.
- Add high availability only where interruption is unacceptable.
That order keeps resilience tied to business risk rather than infrastructure fashion.
RTO and RPO Make the Decision Practical
RTO and RPO are the two most useful terms in resilience planning.
Recovery Time Objective, or RTO, means how long the business can tolerate the workload being unavailable.
Recovery Point Objective, or RPO, means how much data the business can tolerate losing.
These two numbers turn vague concerns into practical decisions.
| Business question | Metric | Example |
|---|---|---|
| How long can this be down? | RTO | 15 minutes, 4 hours, 1 business day |
| How much data can we lose? | RPO | 5 minutes, 1 hour, 24 hours |
| How quickly must users return? | RTO | Customer portal back within 30 minutes |
| How fresh must restored data be? | RPO | Database restored to within 15 minutes |
A low RTO usually pushes the team toward high availability, failover, monitoring, and faster incident response.
A low RPO usually pushes the team toward more frequent backups, database replication, snapshots, log shipping, or stronger data protection.
For example:
| Workload | Possible RTO | Possible RPO | What it suggests |
|---|---|---|---|
| Marketing website | 8 hours | 24 hours | Backups and restore plan may be enough |
| Internal dashboard | 4 hours | 24 hours | Daily backup and monitoring |
| Customer portal | 1 hour | 15 minutes | Strong backups and possible HA |
| Accounting system | 4 hours | 1 hour | Recovery planning matters more than HA |
| Remote desktop for staff | 2 hours | 1 hour | Backups, restore plan, access continuity |
| Production SaaS database | 15 minutes | 5 minutes | HA, replication, and DR planning |
Small teams should not guess these values in technical isolation. Ask the business owner, support team, operations lead, or customer-facing team what downtime and data loss actually mean.
If nobody can answer, the workload is not ready for expensive HA. It is ready for a business impact review.
What High Availability Actually Protects
High availability protects against interruptions caused by routine failures.
That may include:
- one VM failing,
- one application process crashing,
- one load balancer target becoming unhealthy,
- one database replica becoming unavailable,
- one region or zone issue in larger architectures,
- one deployment target being temporarily removed,
- or one component needing maintenance.
A basic high-availability design may use multiple application servers behind a load balancer. A more advanced design may add database replication, health checks, automated failover, multi-zone deployment, or multi-region architecture.
The purpose is not to make failure impossible. The purpose is to keep the service available when a known failure happens.
High availability is useful when interruption itself is costly.
Examples:
| Workload | Why HA may matter |
|---|---|
| Customer portal | Customers expect access during business hours |
| Public API | Clients may depend on consistent responses |
| E-commerce checkout | Downtime directly affects revenue |
| SaaS dashboard | Users may rely on the app throughout the day |
| Remote desktop environment | Staff may be unable to work if unavailable |
| Booking or scheduling system | Missed appointments or orders create business loss |
But HA has limits.
It does not automatically protect against bad deployments, data corruption, accidental deletion, ransomware, misconfiguration, or a broken database write that replicates across nodes.
That is why high availability without disaster recovery creates a false sense of safety.
What Disaster Recovery Actually Protects
Disaster recovery protects the business’s ability to restore service after a serious incident.
That incident may be caused by infrastructure failure, data corruption, accidental deletion, bad migration, security compromise, application bug, lost credentials, provider issue, or human error.
A disaster recovery plan usually includes:
- backups,
- snapshots,
- restore procedure,
- recovery owner,
- recovery environment,
- data retention policy,
- off-server or isolated storage,
- documentation,
- and restore testing.
The key word is restore.
A backup strategy is not complete because backup jobs run. It is complete when the team can restore the workload within the agreed RTO and RPO.
For small businesses, disaster recovery is often more important than high availability at the beginning. A business can often tolerate a short outage. It may not survive losing customer data, accounting data, operational records, or application state.
Examples:
| Workload | DR focus |
|---|---|
| Accounting app | Restore company data and user access |
| Database-backed website | Restore database and application config |
| Internal dashboard | Restore data sources and scheduled jobs |
| File workflow | Restore files, permissions, and folder structure |
| Windows VM | Restore application, users, data, and RDP access |
| Self-hosted tool | Restore container config, database, and secrets |
Disaster recovery should be designed before the first serious incident, not during it.
For deeper backup planning, read Cloud Server Backup Strategies.
Why Most SMBs Should Start With Recovery First
Many small businesses think resilience means “never go down.” In practice, the first milestone should usually be “we can recover.”
Recovery-first planning is more realistic because it protects against the failures small teams actually experience:
- accidental deletion,
- bad updates,
- server misconfiguration,
- failed migration,
- ransomware or compromise,
- lost files,
- broken database,
- expired credentials,
- and one old office server failing.
High availability may reduce interruption during routine failures, but it does not help if the team cannot restore the data.
A small business replacing an office server should usually ask these questions before buying HA architecture:
| Question | Why it matters |
|---|---|
| Do we know what data matters? | Defines backup scope |
| Do we know how often it changes? | Defines RPO |
| Do we know how long restore can take? | Defines RTO |
| Have we tested restore? | Proves recovery works |
| Do we know who owns recovery? | Prevents confusion during failure |
| Is the old system documented? | Prevents hidden dependency risk |
Once those answers are clear, HA becomes easier to evaluate.
Recovery first does not mean availability is unimportant. It means the foundation should be recoverability before redundancy.
When High Availability Becomes Worth It Earlier
Some small-team workloads justify HA earlier.
The signal is not company size. The signal is business impact.
High availability becomes worth evaluating when:
- customers cannot use a paid product during downtime,
- a public API has contractual or operational expectations,
- staff cannot work without the system,
- revenue stops during outage,
- downtime damages trust,
- the application supports live operations,
- or the cost of interruption is higher than the cost of HA.
A small company with one critical customer portal may need HA sooner than a larger company with mostly internal tools.
Use this decision table:
| Situation | HA priority |
|---|---|
| Internal tool used occasionally | Low |
| Internal dashboard used daily | Medium |
| Customer-facing app during business hours | Medium to high |
| Revenue-critical checkout or booking | High |
| Remote desktop environment for daily staff work | Medium to high |
| Public API used by customers | High |
| Database with strict uptime requirement | High, but DR still required |
HA should be added where interruption hurts enough to justify extra complexity.
The mistake is adding HA everywhere. That increases cost and operational burden without matching business value.
A Practical Comparison for Small Teams
Here is the simplest way to compare HA and DR.
| Factor | High availability | Disaster recovery |
|---|---|---|
| Main goal | Keep service running | Restore service after failure |
| Primary metric | Uptime / interruption | RTO and RPO |
| Common tools | Load balancers, replicas, health checks, failover | Backups, snapshots, restore plans, retention |
| Protects against | Routine component failure | Serious incidents, data loss, rebuild scenarios |
| Does not solve | Data corruption, accidental deletion, bad replicated changes | Continuous uptime during routine failures |
| Cost pattern | More live infrastructure | Storage, backup, testing, documentation |
| Best first for | Revenue-critical live services | Most small business workloads |
| Needs testing? | Failover testing | Restore testing |
The important sentence is this:
HA keeps the service running when something small fails; DR gets the service back when something serious breaks.
Small teams need both eventually for important production systems. But they do not always need both at the same level on day one.
The Most Common Small-Team Mistake
The most common mistake is buying high availability before proving disaster recovery.
A team adds a second server, load balancer, or replica and feels safer. But the backups are untested. The database restore process is unclear. Secrets are not documented. DNS access depends on one person. The application can fail over, but nobody knows how to rebuild it if corrupted data or a bad deployment affects both nodes.
That is not resilience. It is redundancy without recovery.
The second common mistake is assuming backups are enough. Backups protect data, but they do not automatically restore service quickly. A team may have the data but still need hours or days to rebuild the application, reconfigure DNS, recover credentials, reinstall dependencies, or recreate users.
Real resilience connects both sides:
| Control | What it proves |
|---|---|
| Backups | Data can be copied |
| Restore test | Data can be recovered |
| Runbook | People know what to do |
| Monitoring | Problems are detected |
| Snapshots | Risky changes can be rolled back |
| HA design | Routine failures do not stop service |
| DR plan | Serious incidents can be recovered from |
For small teams, the best improvement is often not a new architecture. It is a restore test.
How Raff Fits HA and DR Planning
Raff Technologies fits small-team resilience planning by giving teams practical infrastructure controls without forcing enterprise architecture too early.
For Linux workloads, Raff VMs are a strong fit for websites, APIs, internal dashboards, databases, automation services, self-hosted tools, and customer portals. Linux VMs include full root access, SSH key authentication, Docker-ready infrastructure, NVMe SSD storage, unmetered bandwidth, DDoS protection, cloud firewall, and fast deployment.
For Windows workloads, Raff Windows VMs are useful when a small business needs Remote Desktop, Windows Server, IIS, .NET, MSSQL planning, accounting software, trading platforms, or Windows-only business applications. Windows workloads often need special attention because RDP access, user sessions, licensing, and application data all affect recovery planning.
Raff cloud servers start from $3.99/month and use AMD EPYC processors, NVMe SSD storage, and unmetered bandwidth. Raff VMs can be paired with snapshots and scheduled backups, which makes recovery planning easier to include from the beginning.
The design rationale is simple: small teams should not overbuild before they can recover. Start with a VM that has clear ownership, monitoring, backups, restore testing, and documented access. Then add higher-availability patterns where the business impact justifies the extra architecture.
A practical Raff resilience path looks like this:
| Stage | What to build |
|---|---|
| Recovery first | Backups, snapshots, restore test, owner, documentation |
| Better detection | Uptime monitoring, alerts, log review, health checks |
| Safer changes | Snapshots before updates, rollback procedure, staging VM |
| Availability layer | Load balancing, multiple app nodes, replica design where needed |
| Business continuity | Clear RTO/RPO targets, runbook, periodic recovery testing |
This approach lets SMBs protect real workloads without pretending every system needs enterprise-grade HA on day one.
Best Practices for Building Both Without Overbuilding
Start with business impact, not architecture fashion
Do not ask, “Should we use HA?” first. Ask, “What happens if this workload is down?”
If the impact is low, start with backups and documentation. If the impact is high, define RTO and RPO, then decide whether HA, DR, or both are needed.
Protect data separately from runtime
A running server and protected data are different things.
Snapshots, backups, database dumps, object storage, and off-server copies may all play a role. The important point is that data protection should survive server failure, bad updates, and accidental deletion.
Keep the blast radius small
Avoid putting every business process on one VM with no separation.
A small team can still keep architecture simple while separating high-risk workloads from low-risk ones. For example, a customer portal, internal dashboard, and automation service may not all need to fail together.
Test restores, not just backups
A backup that has never been restored is an assumption.
Test restores on a schedule. Confirm that files, databases, configuration, users, and application behavior return correctly.
Add high availability where interruptions actually hurt
HA is valuable when downtime has real cost.
Add it to customer-facing systems, revenue-critical services, public APIs, or remote work environments where interruption stops the business. Do not add it everywhere just to feel safer.
Document recovery ownership
During an incident, the most dangerous phrase is “I thought someone else had it.”
Every critical workload should have a named owner, backup location, restore procedure, and escalation path.
A Practical HA and DR Checklist
Use this checklist for every important workload.
Business impact
- What business process does this workload support?
- Who uses it?
- Is it customer-facing or internal?
- What happens if it is down for 15 minutes?
- What happens if it is down for 4 hours?
- What happens if it loses one day of data?
Recovery planning
- What data must be backed up?
- How often does the data change?
- What is the RPO?
- What is the RTO?
- Where are backups stored?
- How long are backups retained?
- Has restore been tested?
- Who owns recovery?
Availability planning
- Does the workload need to stay online during routine failure?
- Is there a load balancer or failover path?
- Are health checks meaningful?
- Is the database a single point of failure?
- Can users tolerate reconnecting?
- What monitoring detects downtime?
Operational planning
- Is the architecture documented?
- Are credentials stored safely?
- Are updates tested before production?
- Are snapshots used before risky changes?
- Is there a runbook?
- Is the old environment or fallback path available when needed?
This checklist is not about perfection. It is about making resilience visible before failure.
Conclusion
High availability and disaster recovery are both important, but they solve different problems. High availability reduces interruption during routine failures. Disaster recovery restores service after larger incidents, data loss, or broken environments.
For small teams and SMBs, the most practical path is usually recovery first. Define RTO and RPO, protect the data, test restores, document ownership, add monitoring, and then invest in high availability where downtime clearly hurts customers, revenue, staff work, or operations.
This guide connects into Raff’s Cloud Servers for Small Business cluster. If you are planning a migration, read Cloud Migration Checklist for Small Teams. If you are replacing old office hardware, read Office Server Replacement Guide. If you are estimating the cost of resilience, read Cloud Server Cost in 2026.
If your team needs a practical foundation for backup, recovery, monitoring, and cloud workload resilience, Raff Technologies gives you Linux and Windows cloud VMs with transparent pricing, snapshots, backups, fast deployment, and infrastructure designed to stay simple while your reliability needs grow.