Kubernetes cost optimization is the discipline of reducing cluster spend without making the system slower, riskier, or harder to operate.
For startups and small teams, the painful Kubernetes bill usually does not come from one dramatic mistake. It comes from small operational habits that become expensive together: oversized requests, idle nodes, duplicated environments, always-on preview workloads, databases placed in the wrong layer, logs retained without discipline, and clusters adopted before the workload truly needs Kubernetes.
For Raff Technologies users, the right question is not only "How do we make Kubernetes cheaper?" The better question is "Should this workload be on Kubernetes yet, and if yes, what should actually run inside the cluster?"
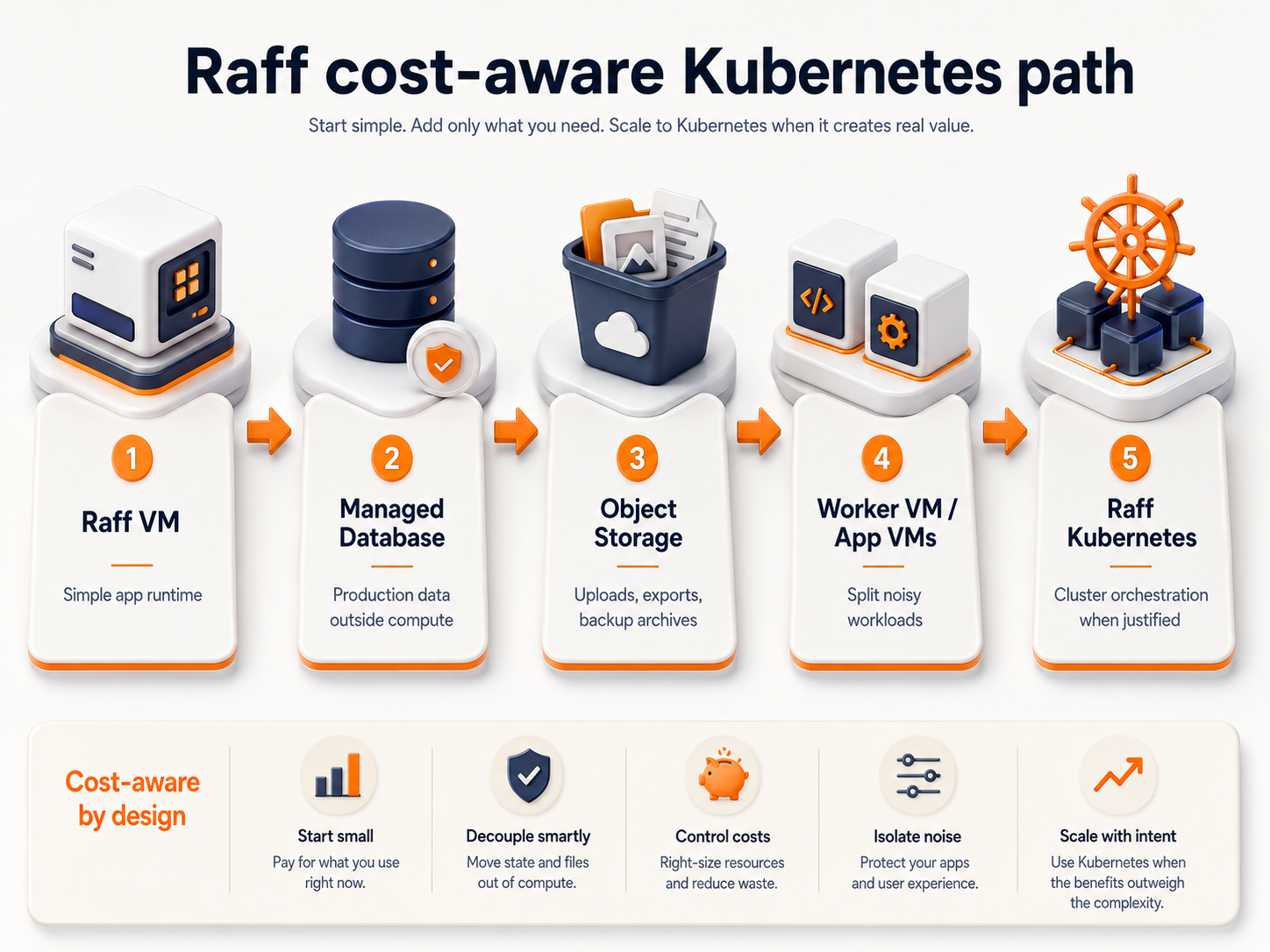
This guide updates the Kubernetes cost conversation around the Raff infrastructure path: start simple on Raff VM, move production data to Raff Managed Databases when database operations matter, use Raff Object Storage for uploads and backup archives, and use Raff Kubernetes when orchestration is justified by real deployment, scaling, and service-management needs.
Before optimizing Kubernetes, read Kubernetes vs Docker Compose for Small Teams. Many cluster cost problems start before the cluster exists.
Kubernetes cost optimization starts before the first cluster
The cheapest Kubernetes cluster is not always the one with the best autoscaler. Sometimes it is the cluster you do not create yet.
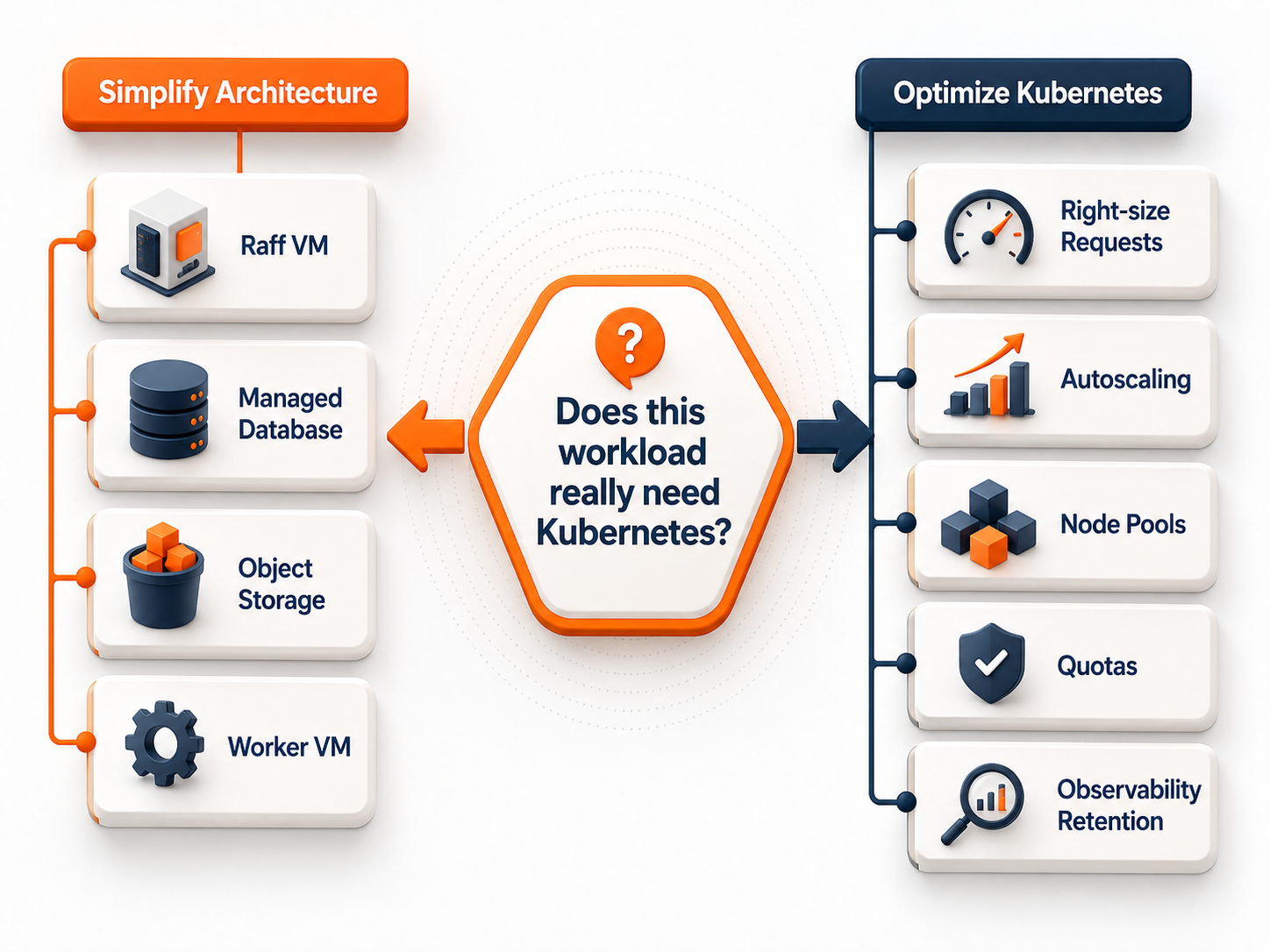
Kubernetes is useful when your team needs cluster-level scheduling, service discovery, rollout controls, self-healing, and consistent workload management across nodes. It is not automatically the right next step after one VM.
For a small SaaS team, there are usually four stages before Kubernetes becomes the natural choice:
- One VM running the app.
- App VM plus managed database.
- App VM plus managed database plus object storage.
- Multi-VM architecture with workers, load balancing, and separated roles.
Only after those stages create real coordination problems does Kubernetes start to earn its operational cost.
That does not make Kubernetes bad. It makes Kubernetes specific.
A cluster should solve a problem that is bigger than a VM-level deployment workflow. If the problem is poor backups, unclear environments, weak CI/CD, oversized infrastructure, or unmeasured workloads, Kubernetes will not automatically fix it. It may make the problem more expensive.
The cluster bill is usually a symptom
When a founder says "our Kubernetes bill is getting painful," the invoice is usually not the root cause.
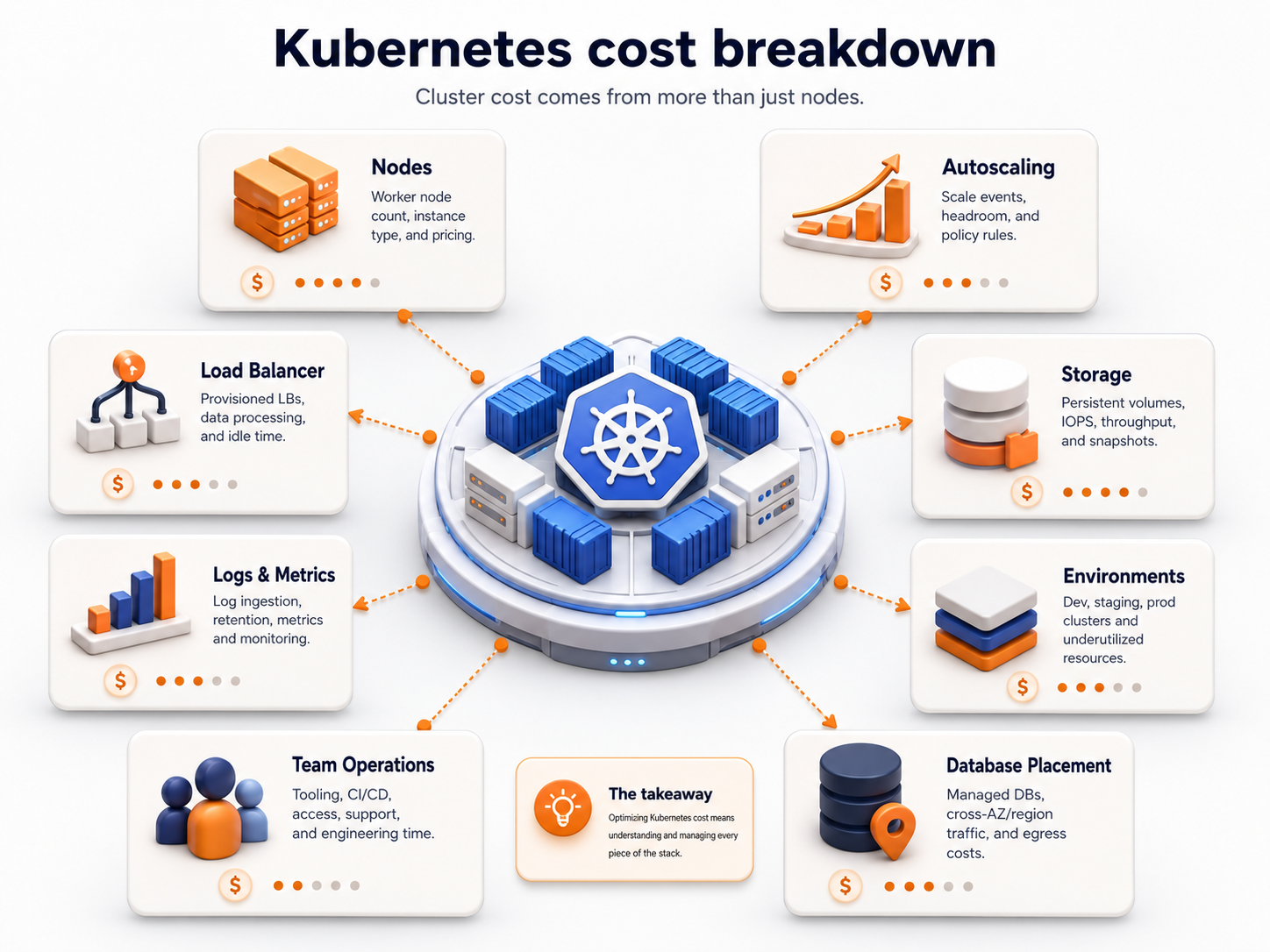
The real causes are usually upstream:
- Workloads sized by fear instead of measurements
- CPU and memory requests copied from staging into production
- Environments running full-time without usage
- Node pools designed for imagined future workloads
- Autoscaling added before right-sizing
- Databases or stateful systems placed inside the cluster too early
- Logs, metrics, and traces retained without policy
- Preview environments kept alive longer than needed
- Teams using Kubernetes when Docker Compose or multi-VM architecture would still be enough
The invoice only makes those decisions visible.
Kubernetes cost optimization should start with workload honesty. What does the app actually need? Which workloads are idle? Which environments are still useful? Which services belong inside the cluster? Which should live in managed databases, object storage, or separate VMs?
That is why this article should not be read as a generic "Kubernetes is expensive" warning. Kubernetes can be the right platform. But it needs operational discipline to stay economical.
The quick decision framework
Use this table before adding another node, autoscaler, environment, or optimization tool.
| Situation | Better first move | Why |
|---|---|---|
| Product is still validating demand | Stay on VM or Docker Compose | Cluster overhead may exceed product value |
| One app needs simple hosting | Raff VM | Simpler cost model and operations |
| Database is creating operational risk | Managed database | Data protection should be solved before cluster tuning |
| Uploads are filling app storage | Object storage | File growth should not drive compute spend |
| Workers slow down web traffic | Worker VM or separate workload | Split the noisy role first |
| Multiple app replicas are needed | Load balancer or Kubernetes | Choose based on coordination complexity |
| Requests are inflated | Right-size requests | Scheduler decisions depend on request values |
| Autoscaling increases cost too fast | Fix workload signals first | Autoscaling can scale waste |
| Many environments are always on | Reduce environment sprawl | Idle environments quietly raise baseline cost |
| Cluster has several teams/namespaces | Add quotas and limits | Shared clusters need cost boundaries |
| Team lacks Kubernetes operators | Delay Kubernetes | Complexity becomes a hidden cost |
| Cluster is justified | Optimize node pools, requests, autoscaling, and retention | Now Kubernetes tuning is worth the effort |
The best cost optimization is not always a Kubernetes setting. Sometimes it is choosing the simpler architecture until the workload proves it needs a cluster.
Requests and limits decide how expensive scheduling becomes
Resource requests and limits are the first place startup Kubernetes cost usually goes wrong.
Kubernetes uses requests to decide where Pods should be scheduled. Limits define the maximum amount of a resource a container can use. The Kubernetes documentation explains that if a node has available capacity, a container can use more than its request, while CPU and memory limits are enforced differently by the system: Kubernetes resource management for Pods and containers.
The cost problem is simple: if requests are inflated, the scheduler believes the cluster is fuller than it really is.
That leads to:
- Lower node utilization
- More nodes than necessary
- Poor bin packing
- Autoscaling decisions based on bad signals
- Expensive "safety" that may not reflect real usage
A startup might set every app container to request more CPU and memory than it uses because nobody wants a production incident. That feels safe, but it can make the cluster pay for capacity that workloads rarely touch.
The better process is:
- Measure actual CPU and memory usage.
- Set initial requests from observed behavior.
- Keep limits deliberate, not copied blindly.
- Review request-to-usage ratios regularly.
- Separate workload classes instead of making every service look equally important.
A request is not just a technical value. It is a cost signal.
Autoscaling helps only after workload signals are honest
Autoscaling is useful, but it is not magic.
The Horizontal Pod Autoscaler adjusts the desired number of replicas for a target workload based on observed metrics such as CPU, memory, or custom metrics: Kubernetes Horizontal Pod Autoscaling.
That is powerful when the metrics reflect real demand. It is expensive when the metrics are distorted by bad requests, noisy jobs, missing limits, or application behavior that should be fixed first.
Autoscaling can create cost problems when:
- Minimum replica counts are too high
- CPU targets are set without traffic context
- Background jobs trigger scaling meant for web traffic
- Services scale out because requests are wrong
- Node autoscaling responds to inefficient Pod placement
- Preview or staging environments autoscale like production
- Custom metrics are missing or poorly chosen
A useful rule:
Right-size before autoscaling. Then autoscale only what should actually scale.
For example, a web API may need horizontal scaling based on request load. A reporting worker may need a separate queue-based scaling policy. A scheduled batch job may not need to run all day. Treating all workloads the same makes autoscaling less precise and more expensive.
Autoscaling should follow real demand, not compensate for weak resource discipline.
Environment sprawl raises the baseline cost
Many startup Kubernetes bills grow because every environment becomes permanent.
Production is necessary. Staging is usually necessary. But then preview, QA, internal demo, migration test, performance test, and old experiment environments start staying alive. Each environment may feel small, but together they create a baseline cost that exists before users send any traffic.
Environment sprawl usually looks like this:
Production Staging Preview 1 Preview 2 QA Demo Old test cluster Migration sandbox
The cost is not only nodes. It is also storage, logs, metrics, load balancers, IPs, backups, and team attention.
A better environment policy asks:
- Which environments must run 24/7?
- Which can sleep when not used?
- Which should be destroyed after a pull request closes?
- Which need production-sized resources?
- Which need real databases?
- Which can use smaller data sets?
- Which logs and metrics need long retention?
- Who owns cleanup?
For small teams, environment policy is often cheaper than advanced node optimization.
Do not buy more nodes before deleting workloads that no longer deserve to run.
Node strategy should match workload classes
Node strategy is another place Kubernetes spend can drift.
Some teams make every node pool identical. That is simple, but it may force all workloads into the same cost profile. Other teams create too many node pools, which can reduce placement efficiency and make operations harder.
The better path is to group by real workload classes.
A startup cluster may only need a few categories:
| Workload class | Example | Cost goal |
|---|---|---|
| General app workloads | APIs, web apps, small services | Balanced capacity |
| Memory-heavy workloads | Search, analytics, in-memory services | Avoid starving RAM-heavy Pods |
| Background/batch workloads | Jobs, reports, imports, exports | Flexible capacity and isolation |
| Critical production workloads | Customer-facing services | Predictable placement and reliability |
| Non-production workloads | Staging, previews, QA | Lower baseline cost |
Anything more detailed should have a strong reason.
The point is not to create a complex node taxonomy. The point is to stop mixing workloads with very different cost and reliability profiles when that mixing creates waste.
For Raff users, this connects directly to single VM vs multi-VM SaaS architecture. Even before Kubernetes, role separation helps teams understand workload classes. Kubernetes should formalize that discipline, not replace it.
Quotas and limits turn cluster cost into a boundary
A shared cluster without quotas is easy to overspend.
Kubernetes ResourceQuota objects can limit aggregate resource consumption per namespace, and Kubernetes documentation describes them as a way to address the concern that one team or workload could use more than its fair share of resources in a fixed-size cluster: Kubernetes Resource Quotas.
LimitRanges can also define default, minimum, and maximum resource constraints inside a namespace: Kubernetes Limit Ranges.
For startups, quotas are not only platform controls. They are financial boundaries.
Use quotas when:
- Multiple teams share a cluster
- Preview environments are created often
- Staging can accidentally grow too large
- One namespace contains experimental workloads
- CI/CD jobs run inside the cluster
- A team wants to limit blast radius from mistakes
- You need clearer cost ownership
A simple model:
production namespace = protected resources staging namespace = smaller quota preview namespace = strict quota and cleanup policy jobs namespace = controlled batch capacity
That prevents "temporary" workloads from becoming permanent budget leaks.
Databases can make Kubernetes cost worse when placed too early inside the cluster
Running databases inside Kubernetes can work, but small teams should be careful.
Databases have different requirements from stateless app containers. They need durable storage, backup discipline, restore testing, upgrade planning, monitoring, and careful failure handling. If the team is still learning Kubernetes, putting the production database inside the cluster can increase both cost and risk.
A cleaner early pattern is:
Kubernetes or app VMs ↓ private access Raff Managed Database
This keeps the app workloads in the orchestration layer while database operations live in a database-focused service.
Use Raff Managed Databases when the team wants PostgreSQL, MySQL, or Redis without operating the database host. Use a self-hosted database VM when full control is needed and the team can handle backups, patches, monitoring, and restore.
For the full database decision, read Managed vs Self-Hosted Databases and Database Backup Strategy for SaaS Apps.
Kubernetes cost optimization is easier when the cluster is not also carrying database complexity before the team is ready.
Object storage prevents file growth from becoming cluster cost
User uploads, exports, reports, and media should not force compute scaling.
If uploaded files live inside containers, node disks, or application volumes, storage growth can affect scheduling, backups, restore, and cluster cost. For most SaaS apps, the cleaner pattern is to store file metadata in the database and file bodies in object storage.
A production pattern looks like this:
App workload ↓ Database stores metadata ↓ Object storage stores uploaded files
Raff Object Storage starts at $7.00/month for the first 100 GB and is S3-compatible at s3.raffusercloud.com.
This keeps file growth out of the cluster's compute layer. The app can run on VMs or Kubernetes while durable files live in object storage.
Use object storage for:
- User uploads
- Profile images
- Product media
- Generated reports
- Exports
- Attachments
- Backup archives
- Files shared across app replicas
For the full storage decision, read App Uploads: VM Disk vs Object Storage for SaaS Teams.