
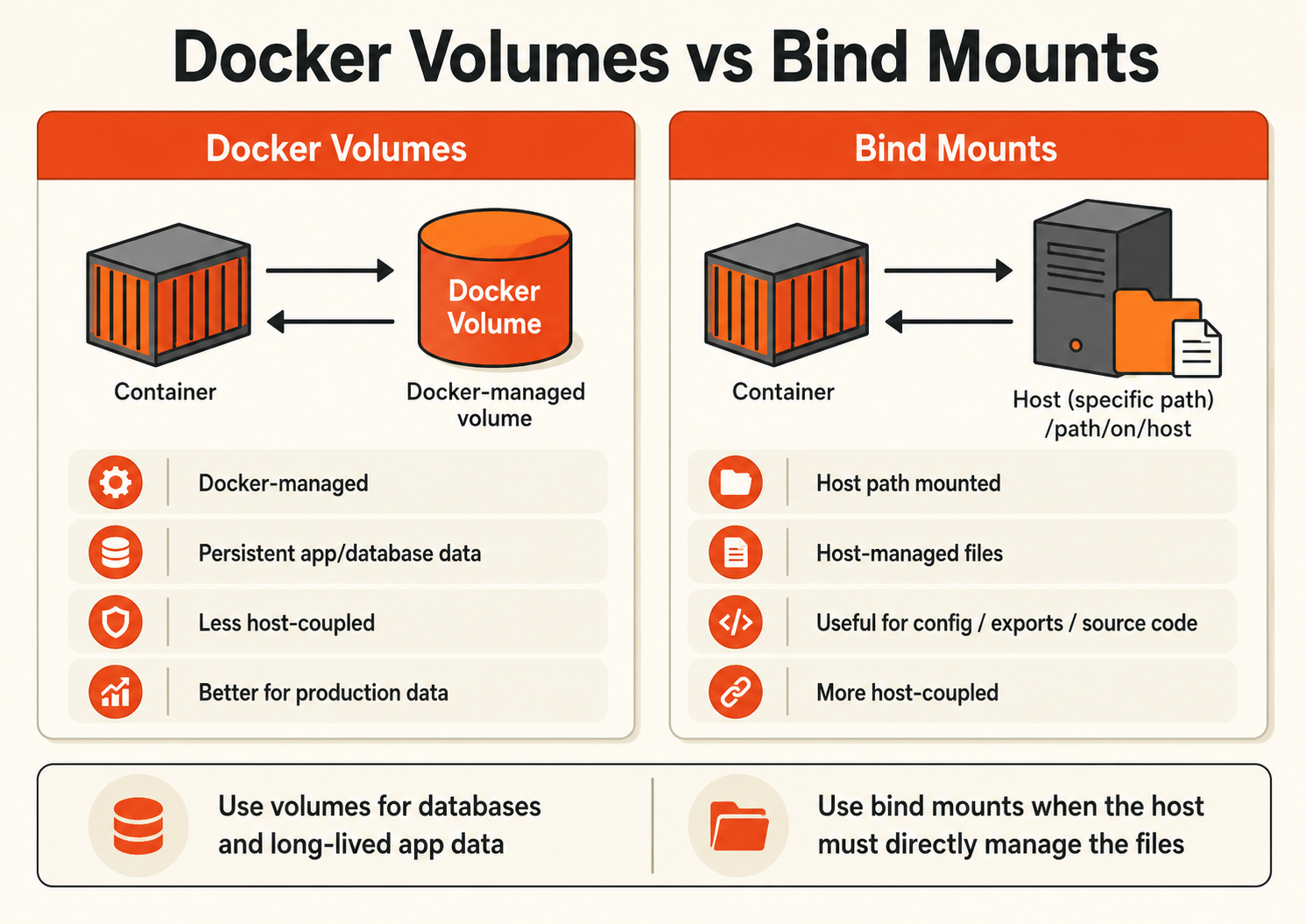
Docker volumes and bind mounts are two ways to persist or share data outside a container’s writable layer.
The practical production answer is simple:
Use Docker volumes for most application data. Use bind mounts only when the host must directly own, edit, inspect, or collect the files.
That distinction matters because production Docker storage is not just about whether data survives a container restart. Both volumes and bind mounts can persist data. The real question is where the storage contract lives.
With a Docker volume, the contract is mostly between Docker and the container.
With a bind mount, the contract is between the host filesystem and the container.
That single difference affects portability, security, backups, rebuilds, migrations, permissions, and how confidently your team can recreate the workload on another server.
This guide explains what Docker volumes and bind mounts are, how they differ in production, when each one makes sense, what teams often get wrong, and how to apply the right pattern on a Raff Linux VM.
Quick answer: Docker volume or bind mount?
Use this section if you need the short version first.
| Situation | Better default | Why |
|---|---|---|
| Database data | Docker volume | Persistent, Docker-managed, less host-coupled |
| Redis or stateful service data | Docker volume | Cleaner container replacement and recovery |
| User uploads inside an app container | Docker volume or object storage | Data should survive image rebuilds |
| App-generated files that must persist | Docker volume | Better production lifecycle |
| Source code during local development | Bind mount | Host edits should appear immediately in the container |
| Host-managed config file | Bind mount, preferably read-only | Host intentionally owns the file |
| TLS certificates from host workflow | Bind mount, preferably read-only | Host process may manage renewals |
| Exported reports or artifacts | Bind mount | Host needs direct file access |
| Logs collected by host agent | Bind mount or logging driver | Depends on logging architecture |
| Temporary data | tmpfs or container-local | Avoid persistence when not needed |
A useful rule:
If the data belongs to the application, start with a named volume. If the file belongs to the host workflow, use a bind mount intentionally.
This rule prevents many production mistakes.
Why container storage needs a decision
Containers are designed to be replaceable.
That is one of Docker’s strengths. You can rebuild an image, replace a container, roll out a new version, and keep the app environment more predictable.
But data changes the story.
If a container writes important data only inside its writable layer, that data is tied to that specific container instance. When the container is removed, replaced, or recreated, the data may disappear or become difficult to recover.
That is why persistent mounts exist.
They keep important files outside the container’s writable layer so the container can change without losing the data.
Common persistent data includes:
- Database files
- User uploads
- Application state
- Generated files
- Queue state
- Cache persistence
- Exported reports
- Host-managed configuration
- Certificates
- Runtime artifacts
- Backup staging directories
The question is not whether you need persistence.
The question is which persistence model creates the least operational risk.
What Docker volumes are
A Docker volume is persistent storage created and managed by Docker.
You give it a name, mount it into a container, and let Docker manage where it lives on the host.
A basic Docker Compose example looks like this:
services: postgres: image: postgres:16 volumes: - postgres_data:/var/lib/postgresql/data volumes: postgres_data:
The application does not need to know the exact host path.
It only needs to know:
postgres_data → /var/lib/postgresql/data
That is why named volumes are cleaner for production. They reduce dependency on a specific directory layout such as /srv, /opt, /data, /home/deploy, or another custom path.
Docker volumes are commonly used for:
- PostgreSQL data
- MySQL data
- Redis persistence
- Application uploads
- Service state
- Internal tool data
- Containerized app storage
- Data that must survive container replacement
Volumes are also easier to reason about with Docker-native workflows. You can list them, inspect them, reuse them, back them up, and attach them to replacement containers.
What bind mounts are
A bind mount maps a specific host file or directory into a container.
A basic Docker Compose example looks like this:
services: app: image: my-app volumes: - ./config/app.yml:/app/config/app.yml:ro
This means:
Host file: ./config/app.yml Container path: /app/config/app.yml Access mode: read-only
The container sees the file, but the file is owned by the host workflow.
That is the strength of bind mounts.
They are useful when the host must directly interact with the files.
Bind mounts are commonly used for:
- Local development source code
- Hot reload workflows
- Host-managed config files
- TLS certificates
- Export directories
- Build artifacts
- Files collected by a host process
- Controlled one-file injection
- Debugging or inspection workflows
The trade-off is host coupling.
If the next server does not have the same path, ownership, permissions, SELinux/AppArmor behavior, or directory structure, the container may fail.
That can be acceptable when intentional. It is dangerous when accidental.
The production difference: storage contract
The biggest difference between volumes and bind mounts is the storage contract.
A named volume says:
Docker manages this storage object. The container mounts it at this path. The application uses it as persistent data.
A bind mount says:
This exact host path must exist. This host path must have the right files. This host path must have the right permissions. The container depends on it.
That difference affects production operations.
| Factor | Docker volumes | Bind mounts |
|---|---|---|
| Storage ownership | Docker-managed | Host-managed |
| Host path dependency | Low | High |
| Production portability | Higher | Lower |
| Best for app data | Strong | Only when host access is required |
| Best for dev source code | Less ideal | Strong |
| Backup workflow | Docker-aware or volume-level | Host path-based |
| Security exposure | Narrower by default | Wider if writable |
| Rebuild safety | Stronger | Depends on host layout |
| Cross-host migration | Cleaner | More manual |
| Read-only config injection | Possible | Strong fit |
This is why named volumes are usually the production default.
Not because bind mounts are bad.
Because bind mounts make the host part of the application contract.
Why volumes are usually safer in production
Docker volumes are usually safer in production because they reduce hidden assumptions.
A production Docker workload should be easy to recreate. If a VM is replaced, a deployment is rebuilt, or a container is updated, the team should know where important data lives and how to restore it.
Named volumes support that pattern better than arbitrary host paths.
They are a strong fit for:
- Databases
- Stateful services
- Production app data
- Internal tools
- Containers that are replaced regularly
- Compose stacks that should be repeatable
- Teams that want fewer host-specific assumptions
For example, a PostgreSQL service should usually use a named volume:
services: db: image: postgres:16 environment: POSTGRES_DB: app POSTGRES_USER: app POSTGRES_PASSWORD: change_me volumes: - postgres_data:/var/lib/postgresql/data volumes: postgres_data:
This keeps the database data outside the container while avoiding a hard dependency on a custom host directory.
It also makes the Compose file more portable.
A new server still needs backup restoration and data handling, but the storage pattern is cleaner.
When bind mounts are the right choice
Bind mounts are the right choice when direct host visibility is part of the design.
This is common in development.
For example:
services: app: build: . volumes: - ./src:/app/src
You edit code on the host. The container sees the change. The development server reloads.
That is exactly what a bind mount is good at.
Bind mounts can also make sense in production when used deliberately.
Good production bind mount use cases include:
- Injecting host-managed config files
- Mounting TLS certificates managed on the host
- Exposing generated files to a host backup process
- Writing reports to a known host directory
- Sharing artifacts between host automation and a container
- Mounting read-only static files
- Giving a host log collector access to a known output path
For configuration, use read-only when possible:
services: app: image: my-app volumes: - /srv/my-app/config.yml:/app/config.yml:ro
The :ro matters.
If the container only needs to read the file, it should not be able to write it.
Security: bind mounts expand blast radius
Bind mounts can create a larger security blast radius because the container receives access to a real host path.
If the mount is writable, a process inside the container can modify files on the host. That may be harmless if the path is an export directory. It may be dangerous if the path is too broad or sensitive.
A bad bind mount looks like this:
volumes: - /:/host
Or this:
volumes: - /etc:/etc
These patterns can expose sensitive host files and create serious risk.
A safer bind mount is narrow and read-only:
volumes: - /srv/my-app/config.yml:/app/config.yml:ro
Production bind mount rules:
- Mount the smallest path possible.
- Use
:rounless write access is required. - Avoid mounting system directories.
- Avoid broad parent directories.
- Document why the bind mount exists.
- Keep ownership and permissions predictable.
- Review bind mounts during security checks.
A bind mount should always have a reason.
If the reason is “because it was easy,” use a named volume instead.
Existing container files can be hidden
Mounts can hide files that already exist inside the container image.
This is a common source of confusion.
Imagine an image contains default files in:
/app/config
Then you bind mount an empty host directory over that path:
volumes: - ./config:/app/config
Inside the running container, the image’s original /app/config contents are hidden by the mounted host directory.
The files are not deleted from the image, but they are no longer visible at that path while the mount is active.
This can break applications that expect default files to exist.
Named volumes have a useful behavior here: when an empty named volume is first mounted into a directory with existing container contents, Docker can copy the existing contents into the volume by default.
That difference matters for images that ship starter data, default configuration, plugins, templates, or initial application files.
Before mounting over a non-empty path, ask:
- Does the image already contain files there?
- Should those files remain visible?
- Should they be copied into a named volume?
- Am I replacing defaults intentionally?
- Will the app still start if the mount is empty?
Mounting over image defaults should be a deliberate decision.
Docker Compose examples
In production, Compose files should make the storage pattern obvious.
Good named volume pattern
Use this for database or app state:
services: db: image: postgres:16 restart: unless-stopped volumes: - db_data:/var/lib/postgresql/data volumes: db_data:
Good read-only bind mount pattern
Use this for host-managed config:
services: app: image: my-app restart: unless-stopped volumes: - /srv/my-app/config.yml:/app/config.yml:ro
Good host export pattern
Use this when the host must collect output files:
services: exporter: image: report-generator restart: unless-stopped volumes: - /srv/reports:/app/reports
Mixed production pattern
A realistic app may use both:
services: app: image: my-app restart: unless-stopped ports: - "127.0.0.1:3000:3000" volumes: - app_uploads:/app/uploads - /srv/my-app/config.yml:/app/config.yml:ro db: image: postgres:16 restart: unless-stopped volumes: - db_data:/var/lib/postgresql/data volumes: app_uploads: db_data:
This is a strong pattern:
- App uploads use a named volume.
- Database data uses a named volume.
- Host-managed config uses a read-only bind mount.
- The application port is bound to localhost only.
The storage design is intentional.
The decision framework
Use this framework before choosing a mount type.
| Question | If yes | If no |
|---|---|---|
| Does the host need to directly edit the files? | Bind mount | Named volume |
| Does the host need to collect generated files? | Bind mount | Named volume |
| Is this database or service state? | Named volume | Continue evaluating |
| Should the data survive container replacement? | Named volume | Maybe container-local or tmpfs |
| Should the deployment work on another host without custom paths? | Named volume | Bind mount may be acceptable |
| Is this a config file controlled by the host? | Read-only bind mount | Named volume or image config |
| Is write access required? | Use narrow writable bind mount only if needed | Use :ro |
| Would losing this data hurt production? | Named volume plus backups | Simpler storage may be enough |
The blunt version:
Databases and long-lived app data should usually use named volumes. Source code, host-managed config, and host-collected artifacts should usually use bind mounts.
Backup strategy matters more than mount type
A Docker volume is not a backup.
A bind mount is not a backup.
Both are storage patterns. Neither one protects you automatically from deletion, corruption, bad migrations, ransomware, broken scripts, or accidental overwrites.
Production storage needs recovery planning.
For named volumes, a simple backup pattern might look like this:
docker run --rm \ -v db_data:/data \ -v $(pwd):/backup \ alpine \ tar czf /backup/db_data_backup.tar.gz -C /data .
For bind mounts, backup may be simpler because the files are already in a host path:
tar czf reports_backup.tar.gz /srv/reports
But backup simplicity does not mean operational safety.
You still need:
- Backup schedule
- Retention policy
- Restore test
- Off-server backup copy
- Access control
- Monitoring for backup failures
- Documentation
- Snapshots before risky changes
For databases, use database-aware backups where appropriate. A file copy of a live database directory may not be enough unless the database is stopped or the backup method is designed for consistency.
Common mistakes to avoid
Mistake 1: Using bind mounts everywhere
Bind mounts feel easy because files are visible on the host.
That visibility can create false confidence.
If the data does not need to be edited or collected by the host, a named volume is usually cleaner.
Mistake 2: Treating volumes as mysterious
Named volumes are not invisible magic.
Docker gives you commands to inspect and manage them:
docker volume ls docker volume inspect volume_name
You can back them up, mount them into helper containers, and reuse them across container replacements.
Mistake 3: Mounting over defaults accidentally
Mounting a host path over a non-empty image directory can hide the image’s default files.
This often breaks first-time setup.
Check the image path before mounting over it.
Mistake 4: Leaving config bind mounts writable
If a container only needs to read a config file, mount it read-only.
Use:
volumes: - /srv/app/config.yml:/app/config.yml:ro
Not:
volumes: - /srv/app/config.yml:/app/config.yml
Mistake 5: Forgetting permissions
Bind mounts often fail because of ownership and permissions.
The host path may exist, but the container user may not be able to read or write it.
Before deployment, check:
ls -la /srv/my-app
Then confirm which user the container runs as.
Mistake 6: Confusing persistence with recovery
Persistent data can persist in a broken state.
Backups and restore tests are still required.
Mistake 7: Using anonymous volumes unintentionally
Anonymous volumes can persist after containers are removed, but they are harder to identify later.
For production, prefer named volumes so the storage purpose is clear.
Best practices for production Docker storage
Use these rules for production workloads.
Use named volumes for application state
If the data belongs to the application and should survive container replacement, use a named volume.
This includes databases, uploads, persistent service state, and durable runtime data.
Use bind mounts intentionally
A bind mount should exist because the host needs the file.
Not because it was convenient during development.
Use read-only bind mounts for config
Configuration files often do not need container write access.
Mount them with :ro wherever possible.
Keep app runtime ports private
Storage is only one part of production safety.
If your app runs behind Nginx, Caddy, or another reverse proxy, bind it to localhost or a private network.
Document mount ownership
Every persistent mount should answer:
- What owns this data?
- Why is it mounted?
- Is it backed up?
- Can it be restored?
- Is write access required?
- Can this workload move to another VM?
Test restores
A backup strategy is unfinished until restore has been tested.
Do not wait for an incident to discover whether the volume can actually be recovered.
How this applies on Raff Technologies
On Raff, Docker volumes and bind mounts both work well because you are working with a real Linux VM environment: full root access, SSH, NVMe SSD storage, firewall control, snapshots, backups, and predictable VM sizing.
That makes Raff a practical place to run Docker Compose workloads, internal tools, APIs, staging environments, self-hosted apps, small SaaS products, and containerized databases.
A strong Raff Docker storage pattern looks like this:
- Named volumes for database data
- Named volumes for long-lived application data
- Read-only bind mounts for host-managed config
- Narrow writable bind mounts only when the host must collect files
- VM snapshots before risky upgrades
- Scheduled backups for business-critical data
- Firewall rules that expose only needed public ports
- Monitoring for disk growth and container health
For a simple production app on a Raff Linux VM, a clean Compose pattern might be:
services: app: image: my-app restart: unless-stopped ports: - "127.0.0.1:3000:3000" volumes: - app_uploads:/app/uploads - /srv/my-app/config.yml:/app/config.yml:ro db: image: postgres:16 restart: unless-stopped volumes: - db_data:/var/lib/postgresql/data volumes: app_uploads: db_data:
This keeps production data Docker-managed while preserving a controlled host-owned config path.
The important point is that Docker storage is not separate from infrastructure planning.
Your VM size, disk capacity, backup schedule, snapshot policy, firewall rules, and monitoring all matter.
Raff gives you the VM foundation. Docker gives you the container runtime. Your storage design decides how safely the workload survives change.
Production checklist
Before running Docker storage in production, review this checklist:
- Are databases using named volumes?
- Are long-lived app files using named volumes?
- Are bind mounts used only where host access is required?
- Are config bind mounts read-only?
- Are writable bind mounts narrow and documented?
- Are you avoiding broad host mounts?
- Are mount paths documented?
- Are permissions tested?
- Are backups configured?
- Have restores been tested?
- Are VM snapshots used before risky changes?
- Is disk growth monitored?
- Are old anonymous volumes cleaned up?
- Are app runtime ports kept private?
- Can the workload be recreated on a new VM?
If a mount exists and nobody can explain why, review it.
Production storage should be boring, documented, and recoverable.
Conclusion
Docker volumes vs bind mounts is not a debate about which one is more real.
Both can persist data.
The difference is operational responsibility.
Docker volumes are usually the safer production default because they are Docker-managed, less dependent on one host’s directory layout, and cleaner for container replacement. Bind mounts are still valuable when the host must directly own, edit, inspect, or collect files.
Use named volumes for databases and long-lived app state. Use bind mounts intentionally for host-owned files. Use read-only bind mounts wherever possible. Avoid broad writable host mounts. Pair the storage pattern with backups, snapshots, monitoring, and restore tests.
On Raff Technologies, this gives teams a clean production model: run Docker on a reliable Linux VM, keep application state in named volumes, use bind mounts only where host-level access is part of the design, and protect the whole workload with proper infrastructure recovery planning.