
App uploads object storage decisions are about where user files should live once your application moves from demo to production.
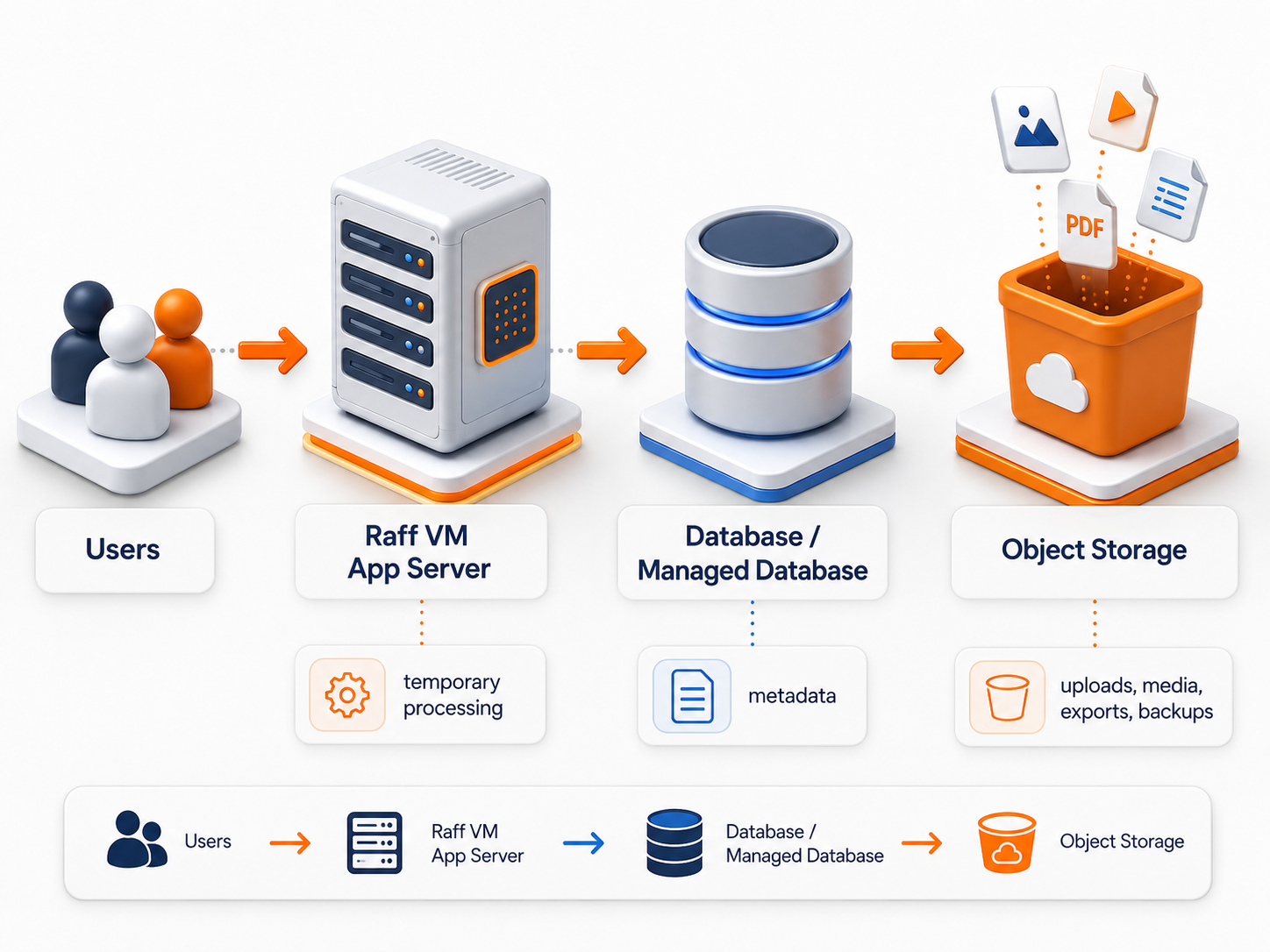
For a SaaS app, uploaded files are not the same as app code, database records, or temporary server files. Raff Technologies gives teams both building blocks: Raff VMs for application compute and Raff Object Storage for S3-compatible file storage when uploads, exports, media, and backups should not live on the app server disk.
Raff Object Storage starts at $7.00/month for the first 100 GB, with S3-compatible access at s3.raffusercloud.com. This guide explains when VM disk is still acceptable, when object storage becomes the safer default, and how small teams should design uploads before storage growth turns into a production problem.
This guide is intentionally narrow. For the broader storage comparison, read Object Storage vs Block Storage vs VM Disk. For developer use cases beyond uploads, read S3-Compatible Object Storage Use Cases for Developers.
App uploads are not the same as app code or database data
App uploads are user-created files that your product receives, stores, serves, processes, or exports.
Examples include:
- Profile images
- PDF documents
- Product photos
- CSV imports
- Generated reports
- Invoices
- Audio files
- Video files
- Design assets
- Backup archives
- User attachments
- Exported datasets
These files behave differently from app code and database records.
App code is replaceable. You can redeploy it from Git. Database records are structured data. They belong in PostgreSQL, MySQL, Redis, or another database system depending on the workload. Uploads are usually binary objects with different access, backup, lifecycle, and growth patterns.
That difference matters because many early apps start with a simple path like this:
App VM ↓ /var/www/app/uploads
That can work at first. It is simple, fast, and easy to debug. But once users depend on uploaded files, the upload folder becomes production data. It needs backup, access control, lifecycle planning, migration strategy, and growth monitoring.
At Raff, we treat uploads as a separate architecture decision because compute should be replaceable, while customer files should survive server rebuilds, app deploys, and VM migrations.
The quick decision framework
Use this table if you need the decision first.

| Situation | Better default | Why |
|---|---|---|
| Prototype or demo | VM disk | Simple and fast to build |
| Internal tool with a few files | VM disk | Low risk if backups exist |
| Early MVP with small uploads | VM disk can work temporarily | Acceptable if you define an exit point |
| User uploads are part of the product | Object storage | Files should not depend on one app server |
| Uploads are growing unpredictably | Object storage | Storage can grow separately from compute |
| App needs multiple servers | Object storage | All app instances can access the same files |
| Files must survive VM rebuilds | Object storage | Files are decoupled from the app server |
| Large media, reports, or exports | Object storage | Better fit for object-style file access |
| Backups are becoming difficult | Object storage | Reduces pressure on VM backup size and restore time |
| Files are private and need signed access | Object storage | S3-compatible workflows can support controlled file access |
| Files are temporary only | VM disk | Local disk is fine for cache, staging, and transient files |
| Files need database relationships | Database stores metadata, object storage stores file | Keep structured records and binary files separate |
The safest production rule is simple:
Store upload metadata in the database. Store the uploaded file itself in object storage when the file matters to users.
That pattern keeps the database focused on structured records and keeps the app server from becoming a file warehouse.
VM disk works for early uploads but creates limits
VM disk is the simplest place to start.
The app writes files to a local folder, stores the path in the database, and serves files through the web server or application. For small projects, this is often enough.
VM disk is acceptable when:
- The app is a prototype
- Uploads are small
- Files are not business-critical
- Only one app server exists
- The team can restore the VM quickly
- Disk growth is predictable
- Uploads are temporary or easy to regenerate
- The product does not depend heavily on user files
A local upload path is easy to understand:
User uploads file ↓ App receives file ↓ VM disk stores file ↓ Database stores file path
The weakness appears when the product grows.
VM disk ties user files to one server. If you rebuild the VM, resize infrastructure, add another app server, or recover from a failure, file handling becomes harder. Uploads also compete with app code, logs, temporary files, database files, package caches, and backups for the same disk.
The most common VM-disk upload problems are predictable:
- Uploads fill the app server disk
- Backups become large and slow
- Restores take longer than expected
- New app servers cannot see old uploads
- Deployments accidentally affect upload paths
- File permissions become fragile
- Logs and uploads compete for storage
- Migration becomes harder after users upload real data
A VM disk upload path should have an exit point before production grows.
Use a trigger like:
- Move uploads when user files become part of the core product.
- Move uploads when disk growth becomes unpredictable.
- Move uploads when backups become too large or slow.
- Move uploads before adding a second app server.
- Move uploads when files must survive VM rebuilds.
- Move uploads when customers depend on file retention.
The problem is not starting on VM disk. The problem is staying there after uploads become production data.
Object storage is the safer default for production uploads
Object storage is usually the better home for production app uploads.
Instead of storing files inside the app VM, the app stores files as objects inside a bucket. The database stores metadata: owner, filename, object key, content type, size, permission state, creation time, and any business relationship.
A clean production pattern looks like this:
User uploads file ↓ App validates file ↓ Object storage stores file ↓ Database stores metadata and object key
Object storage is stronger when uploads matter because it separates file growth from app compute.
The app VM can be resized, rebuilt, replaced, or duplicated without moving every uploaded file. User files live in a storage layer designed for object-style access. The app keeps control through metadata, permissions, and signed URLs.
AWS S3 documentation describes presigned URLs as a way to grant time-limited access to an object without making it public: AWS S3 presigned URL documentation. S3-compatible storage follows the same general API pattern, which is why many applications can use familiar S3 SDKs and tools with compatible endpoints.
Object storage is a better fit when:
- Users upload files regularly
- Upload volume is unpredictable
- Files must survive app server rebuilds
- The app may run on more than one VM later
- Private downloads need controlled access
- Files are larger than normal database records
- Backup and restore windows matter
- Exports and reports should not fill VM disk
- Media assets need a separate lifecycle
- The team wants a clearer storage boundary
Raff Object Storage is S3-compatible, so teams can connect common S3-aware libraries, tools, and SDKs to Raff's endpoint instead of building around local disk assumptions.
:::cta Explore Raff Object Storage Use Raff Object Storage for app uploads, exports, media, and backup retention when files should not live on the VM disk. :::
Upload metadata belongs in the database, not the whole file
Do not put large uploaded files directly in the database unless you have a specific reason.
The database should usually store metadata about the upload, not the entire binary object.
A typical upload record might include:
| Field | Purpose |
|---|---|
id | Internal file record |
user_id | File owner or account |
object_key | Object storage path/key |
original_filename | Name shown to the user |
content_type | MIME type |
size_bytes | File size |
visibility | Private, public, team-only, signed access |
checksum | Integrity check |
created_at | Upload time |
deleted_at | Soft deletion or retention workflow |
This lets the database answer application questions:
- Who owns the file?
- Which project does it belong to?
- Can this user access it?
- Has it been scanned or processed?
- Is it active or deleted?
- Where is the object stored?
- Should it be retained or expired?
The object storage layer answers storage questions:
- Where is the binary file?
- How large is it?
- How is it retrieved?
- How is it retained?
- How is it protected?
- How is it deleted?
This separation keeps the database smaller, backups cleaner, and application architecture easier to scale.
Storing binary files inside the database can make sense in narrow cases, such as tiny files that must be transactionally coupled with a record. But for SaaS uploads, media, PDFs, reports, exports, and user attachments, object storage is usually the cleaner long-term design.
App servers should stay replaceable
A good production app server should be replaceable.
If the VM fails, gets rebuilt, needs resizing, or moves into a multi-VM architecture, the team should not panic because uploads are trapped on that disk.
This is the core architecture issue.
When uploads live on the app VM, the app server becomes stateful in a fragile way. It does not only run code. It also becomes the source of truth for user files.
That creates problems during:
- VM rebuilds
- OS upgrades
- Region or server migrations
- Disaster recovery
- Multi-server scaling
- Blue/green deployments
- Load balancing
- App containerization
- Backup restores
- Developer handoffs
A cleaner pattern is:
App server = runtime, workers, validation, routing Database = structured records and upload metadata Object storage = uploaded files and generated assets
That pattern lets the app server remain closer to stateless. It can still have temporary files, caches, and working directories. But user uploads do not depend on one server's local disk.
For the broader app architecture decision, read Single VM vs Multi-VM Architecture for SaaS Apps and Separate App and Database Server.
Backup and restore planning changes with uploads
Uploads can quietly break backup plans.
A VM backup that was fast at 20 GB may become slow at 200 GB after users start uploading files. A restore that was acceptable in staging may become too slow when it includes app code, logs, database files, temp files, and user uploads on the same disk.
Separate uploads from compute when backup and restore time matter.
| Storage pattern | Backup concern | Restore concern |
|---|---|---|
| Uploads on VM disk | VM backup grows with every file | Restoring the VM also restores files |
| Uploads in database | Database backup grows with binary data | Database restore becomes heavier |
| Uploads in object storage | File storage has separate lifecycle | App/database restore can be smaller |
| Uploads with metadata in DB | DB stores relationships, not file bodies | File and record recovery are planned separately |
The right backup model depends on the product. Some uploads are critical. Some can be regenerated. Some need long retention. Some should expire quickly. Some must be private. Some need audit trails.
Object storage gives you a cleaner place to design that lifecycle.
For server backup planning, read Cloud Server Backup Strategy. For storage type selection, read Object Storage vs Block Storage vs VM Disk.
The practical question is:
If the app server disappeared today, would uploaded files disappear with it?
If the answer is yes, the upload architecture is carrying production risk.
Security and permissions need a storage design
Upload security is not just "where do files live?"
It also includes who can upload, who can download, how files are validated, how private files are served, how old files are deleted, and how sensitive data is protected.
For app uploads, review these areas:
- File type validation
- File size limits
- Malware scanning if the risk requires it
- Private vs public access
- Signed or time-limited download URLs
- User/account ownership checks
- Storage bucket permissions
- Object key naming
- Deletion and retention rules
- Logging and audit needs
- Secret management for storage credentials
The OWASP File Upload Cheat Sheet warns that file uploads can introduce risks such as malicious files, public retrieval abuse, storage exhaustion, and parser vulnerabilities: OWASP File Upload Cheat Sheet.
The storage design should support the security model.
A common secure pattern is:
User requests upload ↓ App checks account and file rules ↓ App stores file in private object storage ↓ Database stores metadata and ownership ↓ App serves controlled access when needed
Avoid putting files in a public bucket by default unless the product truly requires public access. Most SaaS uploads should start private, then become accessible only through application logic or signed access flows.
Object storage does not remove application security work. It gives you a better boundary for applying it.
Cost planning should follow upload growth
Upload storage cost should be planned separately from compute cost.
If uploads live on the VM disk, storage growth can force you to resize compute even when CPU and RAM are fine. That creates a bad cost shape: you buy a larger server because files are growing, not because the app needs more compute.
Object storage keeps file capacity separate from VM sizing.
Raff Object Storage starts at $7.00/month for the first 100 GB. Above that, additional storage is priced per GB, and egress is priced separately. That makes object storage easier to plan for file-heavy products than repeatedly resizing the app server for disk capacity.
Use this cost framework:
| Question | If yes | Better default |
|---|---|---|
| Are uploads small and temporary? | Yes | VM disk |
| Are files a core product feature? | Yes | Object storage |
| Is upload growth unpredictable? | Yes | Object storage |
| Is the app VM being resized only for disk? | Yes | Object storage |
| Do files need long retention? | Yes | Object storage |
| Are uploads easy to regenerate? | Yes | VM disk can be acceptable |
| Do files need private controlled access? | Yes | Object storage with app-managed permissions |
| Will multiple app servers need the same files? | Yes | Object storage |
A SaaS app should not scale compute just because user files are growing.
That is the simplest cost reason to move uploads into object storage.
Raff Object Storage is the production path for user files
Raff Object Storage is the right Raff product when app files should not live on the VM disk.
Use Raff Object Storage for:
- User uploads
- Profile images
- Product media
- PDF documents
- Generated reports
- Exports
- Attachments
- Static assets
- Backup retention
- Large application files
- Files shared across app servers
Use Raff VM disk for:
- App code
- Runtime files
- Package cache
- Temporary uploads before validation
- Local processing workspace
- Small internal files
- Short-lived cache
- Logs before rotation or forwarding
A production SaaS pattern on Raff looks like this:
Users ↓ Raff VM for app ↓ Raff Managed Database or database VM for metadata ↓ Raff Object Storage for uploads
This pattern keeps the app VM focused on compute, the database focused on structured records, and object storage focused on files.
It also supports future growth. If the app later moves from one VM to multiple VMs, user files already live outside the app server. If the database moves to Raff Managed Databases, upload metadata can stay in the database while file objects remain in object storage.
At Raff, this is the key storage decision for SaaS teams: avoid putting durable user files on infrastructure that you may want to rebuild, resize, replace, or scale independently.
:::cta Explore Raff Object Storage Create a Raff Object Storage bucket when uploads, exports, reports, media, or backup archives should live outside the app VM. :::
The migration path from VM disk to object storage
Moving uploads from VM disk to object storage is easiest when you do it before the upload folder becomes huge.
A practical migration path looks like this:
Stage 1: Local upload folder
The app stores files on the VM disk.
App VM ↓ /uploads
This is fine for prototypes and early MVPs.
The team should still define:
- where uploads live
- how large uploads can be
- whether uploads are backed up
- when uploads should move out of the VM
Stage 2: Metadata cleanup
Before moving files, clean up the database model.
The database should store a file record with ownership, object key or path, file size, content type, and visibility. If the app only stores raw local paths inside random tables, migration becomes harder.
A good migration prepares the database first.
Stage 3: Dual-write or migration window
Move files from local disk to object storage.
For small apps, this can happen in a maintenance window. For larger apps, the app may need to read from both locations during migration, then write new uploads only to object storage.
Stage 4: Object storage as source of truth
Once files are moved and verified, object storage becomes the source of truth for uploaded files.
The VM may still use local temporary storage during upload processing, image resizing, virus scanning, or export generation. But durable uploaded files live in the bucket.
Stage 5: Local cleanup and monitoring
After migration, remove old local files only after verifying access, backups, and user flows.
Monitor:
- upload success rate
- download errors
- object storage usage
- database metadata consistency
- failed file processing jobs
- storage cost growth
- access permission errors
The migration is complete only when the app no longer depends on the old local upload path.
The upload storage checklist
Before launching or migrating app uploads, review this checklist.
- Uploads are separated from app code.
- The team knows which files are temporary and which are durable.
- Durable uploads have a storage location outside the app runtime when needed.
- Upload metadata is stored in the database.
- Large file bodies are not stored directly in the database without a specific reason.
- File size limits are defined.
- File type validation exists.
- Private files are not publicly accessible by default.
- Download permissions are checked by the app.
- Signed or time-limited access is used when needed.
- Object keys or paths are predictable enough to operate but not unsafe.
- Backups and retention rules are defined.
- Restore behavior is documented.
- Upload growth is monitored.
- App VM disk alerts exist if local temp storage is still used.
- Multi-server access is planned before adding more app VMs.
- Migration from VM disk to object storage has a rollback plan.
- Old local upload paths are cleaned up after migration.
- Storage credentials are protected and rotated when needed.
If uploads are part of the product, treat them as production data.
If the app server can be rebuilt without losing uploaded files, the architecture is healthier.
Common mistakes to avoid
Keeping uploads on the app VM for too long
Local upload folders feel simple until the product grows.
The longer user files stay on the app VM, the harder migration becomes. Move uploads before disk growth, multi-server scaling, or recovery pressure forces the decision.
Storing large files inside the database
A database should usually store upload metadata, not the file itself.
Large binary data can make backups heavier, restores slower, and database performance harder to manage. Use object storage for file bodies unless there is a specific reason not to.
Mixing uploads, logs, backups, and app code on one disk
This creates avoidable risk.
If logs grow, uploads suffer. If backups grow, the app server fills. If a restore is needed, everything is tangled together.
Separate data types when the product becomes important.
Making buckets public by default
Most SaaS uploads should not start public.
Use private storage and let the app decide who can access each file. Public object access should be a deliberate product decision, not a default shortcut.
Forgetting temporary files
Even with object storage, the app may use local temporary files for processing.
Temporary folders still need limits, cleanup, and disk monitoring. Otherwise a failed upload or export job can fill the VM disk.
Ignoring deletion and retention
Uploads need lifecycle decisions.
What happens when a user deletes a file? What happens when an account is closed? What happens to generated exports after 30 days? What files must be retained?
Object storage gives you a better place to implement these policies, but the application still needs rules.
App uploads belong where production risk is lowest
App uploads should live where they can grow, be protected, and survive infrastructure changes without turning the app server into a storage bottleneck.
VM disk is fine for prototypes, demos, temporary files, and early MVPs with small upload risk. It stops being the right default when uploaded files become part of the product, backups grow too large, multiple app servers need access, or customer files must survive VM rebuilds.
Object storage is usually the safer production home for user uploads, exports, media, reports, and file-heavy SaaS features.
For Raff teams, the clean pattern is simple: run the app on Raff VM, store structured metadata in a database, and keep durable user files in Raff Object Storage. Review Raff pricing to plan VM, object storage, backup, and data transfer costs together.
:::cta Explore Raff Object Storage Use Raff Object Storage when uploaded files should scale independently from your app VM. :::