
atabase backup strategy for SaaS apps is the plan for protecting production data, restoring it within an acceptable time, and limiting how much data the business can lose after an incident.
For small SaaS teams, database backup strategy is not only a technical task. It is a product reliability decision. Raff Technologies gives teams several building blocks for this path: Raff Managed Databases for PostgreSQL, MySQL, and Redis with database operations handled for you, Raff VMs for self-hosted databases you control, Raff Object Storage for backup retention, and snapshots/backups for server-level recovery.
The mistake many teams make is treating "we have a backup" as the same thing as "we can recover." A backup file is only useful if it is current, protected, restorable, and tied to a clear recovery target.
This guide explains how SaaS teams should think about database backups, RPO, RTO, snapshots, dumps, managed databases, object storage retention, restore testing, and the Raff-specific path for keeping production data recoverable.
For the broader database ownership decision, read Managed vs Self-Hosted Databases. For app/database separation, read Separate App and Database Server.
Database backups are a recovery strategy, not a checkbox
A database backup is a recoverable copy of database data created for a specific failure scenario.
The important word is recoverable. A backup that has never been restored is an assumption. A backup stored next to the database, protected by the same credentials, or missing recent data may look useful until the moment it is needed.
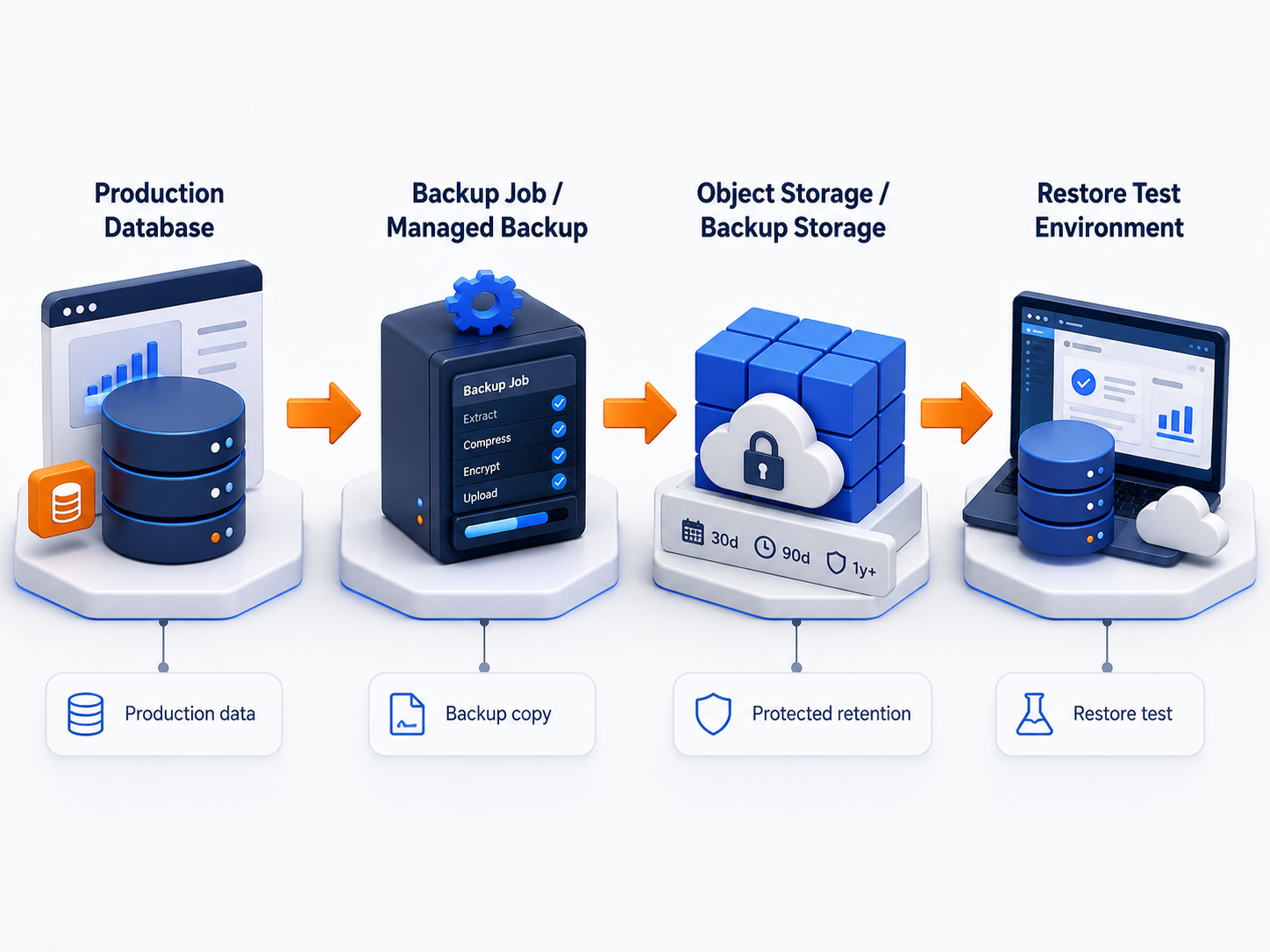 For SaaS teams, database backups must answer practical questions:
For SaaS teams, database backups must answer practical questions:
- What incidents are we protecting against?
- How much data can we afford to lose?
- How long can the app be unavailable?
- Who restores the database?
- Where are backups stored?
- How often are backups created?
- Are backups encrypted or access-controlled?
- Have we tested restore?
- What happens after a bad migration?
- What happens after accidental deletion?
- What happens if the VM or database host is unavailable?
NIST SP 800-34 frames contingency planning around recovery strategies, recovery priorities, and maintaining recovery procedures for information systems: NIST SP 800-34 Rev. 1.
For SaaS apps, the practical version is simple:
The backup strategy should be designed around the business impact of data loss and downtime.
A staging database can have a loose backup policy. A production database with paying customers cannot.
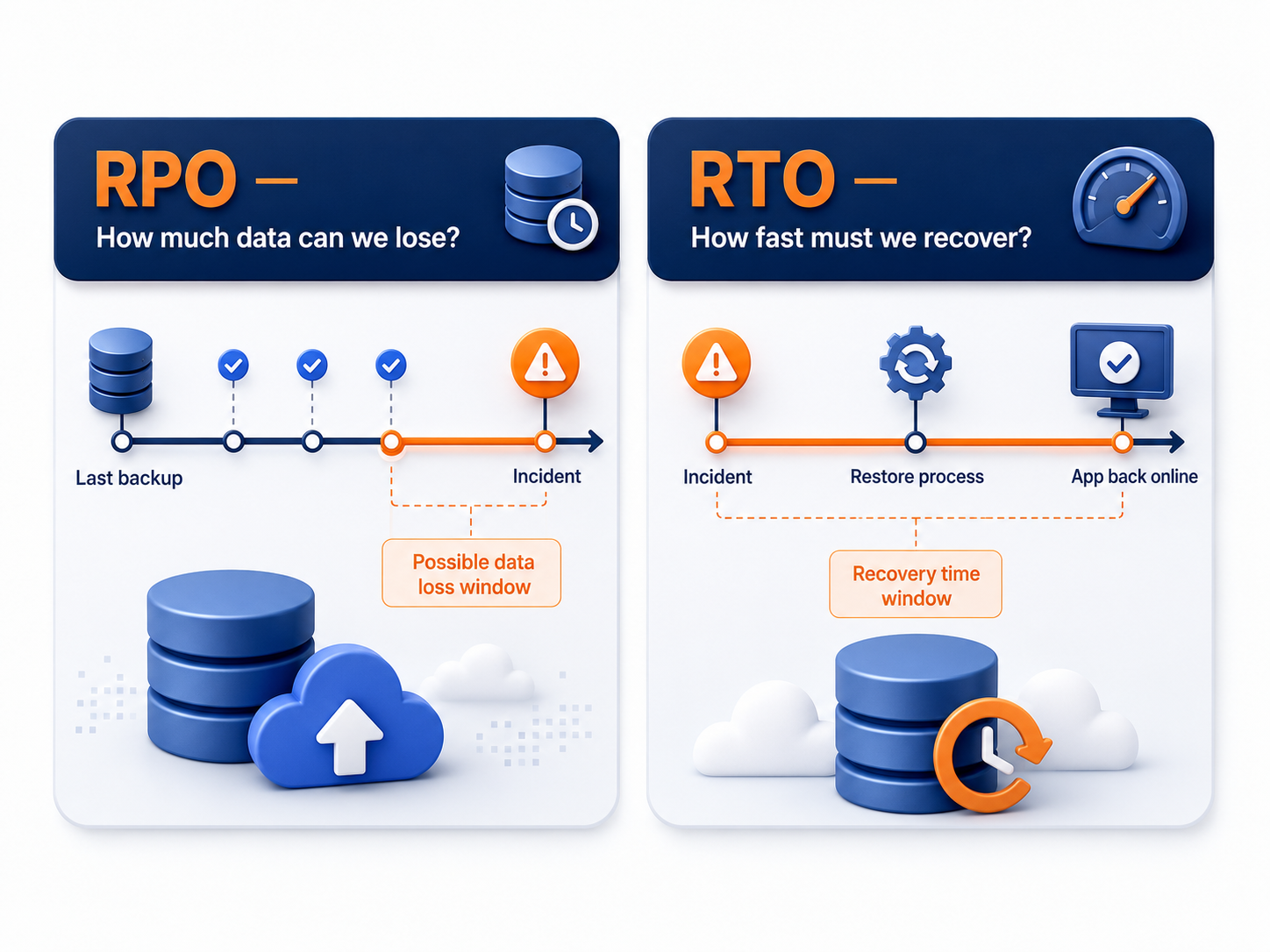
RPO and RTO define the real backup target
A good database backup strategy starts with two numbers: Recovery Point Objective and Recovery Time Objective.
| Term | Meaning | SaaS example |
|---|---|---|
| RPO | Maximum acceptable data loss | "We can lose at most 15 minutes of writes." |
| RTO | Maximum acceptable recovery time | "We need the app back within 1 hour." |
RPO tells you how often data must be captured. RTO tells you how quickly the team must restore service.
These numbers change the architecture.
| Requirement | Backup implication |
|---|---|
| RPO of 24 hours | Daily backup may be acceptable |
| RPO of 1 hour | Hourly backups or continuous archiving may be needed |
| RPO of minutes | Transaction logs, WAL/binlog retention, or managed database features become important |
| RTO of 8 hours | Manual restore may be acceptable |
| RTO of 1 hour | Restore process must be documented and practiced |
| RTO of minutes | High availability or managed failover may be needed |
Do not choose backup frequency randomly. Choose it from RPO.
Do not assume restore speed. Test it against RTO.
A small SaaS app may begin with daily backups. Once customers depend on recent writes, daily backups may no longer be enough. If a customer creates invoices, orders, tickets, messages, or payments throughout the day, losing 24 hours of data can be unacceptable.
SaaS databases need more than one recovery path
One backup method rarely covers every failure scenario.
Different incidents need different recovery tools:
| Incident | Better recovery path |
|---|---|
| Bad app deploy | Roll back app, verify database migrations |
| Bad migration | Pre-migration database backup or point-in-time recovery |
| Accidental row deletion | Point-in-time recovery, audit logs, or selective restore |
| VM failure | Database backup or managed database recovery |
| Disk corruption | Off-server backup |
| Ransomware or credential compromise | Isolated, access-controlled backup retention |
| Region or provider incident | Off-system copy and documented recovery plan |
| User file loss | Object storage retention, not database backup |
| App server failure | VM snapshot or rebuild from code, not database dump |
A database backup strategy should separate three things:
- Database data — structured production records.
- Application runtime — app code, packages, server config, workers.
- User files — uploads, exports, reports, and media.
These should not all rely on the same recovery mechanism.
For user files, read App Uploads: VM Disk vs Object Storage. For server recovery, read Cloud Server Backup Strategy.
Snapshots are useful but not a complete database backup strategy
Snapshots are helpful for server-level recovery, but they should not be the only database backup strategy for production SaaS data.
A snapshot captures disk state at a point in time. That can be useful before risky changes, package upgrades, database migrations, or major deploys. But database engines have their own consistency rules, transaction logs, write-ahead logs, and recovery processes.
PostgreSQL documentation describes three fundamental backup approaches: SQL dump, file system level backup, and continuous archiving: PostgreSQL Backup and Restore.
MySQL documentation separates backup types such as logical versus physical backups and full versus incremental backups, and it also covers scheduling, compression, encryption, and point-in-time recovery: MySQL Backup and Recovery.
The practical lesson: a VM snapshot can be part of the strategy, but database-aware backups are still important.
Use snapshots for:
- Pre-migration rollback safety
- VM-level recovery
- Short-term change protection
- Server configuration recovery
- Fast rollback during planned maintenance
Use database backups for:
- Database restore
- Point-in-time recovery
- Migration recovery
- Selective data recovery
- Moving data between environments
- Long-term retention
- Database-specific recovery workflows
A snapshot answers, "Can I get this server back?"
A database backup answers, "Can I recover this data correctly?"
Those are not the same question.
Logical backups are useful for portability and selective recovery
Logical backups export database contents in a database-aware format.
For PostgreSQL, this often means pg_dump and pg_restore. PostgreSQL documents pg_restore as a tool for restoring a database from an archive created by pg_dump: PostgreSQL pg_restore.
For MySQL, logical backups often use tools such as mysqldump or MySQL Shell dump utilities depending on the environment and scale.
Logical backups are useful because they are portable and easier to inspect. They can help with:
- Moving data between environments
- Restoring one database
- Restoring selected tables in some cases
- Reviewing backup contents
- Migrating between versions with care
- Keeping human-readable or archive-style backups
But logical backups can become slow for large databases. They may lock or stress the database if not configured correctly. They may not meet tight RPO/RTO targets for write-heavy SaaS apps.
Use logical backups when:
- The database is small or medium-sized
- Portability matters
- Restore time is acceptable
- The team wants a clear archive format
- The backup can run without hurting production
Do not rely only on logical backups if the database is large, write-heavy, or needs low data-loss recovery.
Physical backups and continuous archiving support tighter recovery targets
Physical backups copy the database files or storage representation used by the engine. Continuous archiving captures transaction logs so the database can be restored closer to a specific point in time.
This matters when daily or hourly dumps are not enough.
For PostgreSQL, continuous archiving with WAL files is the foundation for point-in-time recovery. For MySQL, binary logs support point-in-time recovery patterns.
Use these approaches when:
- The database is large
- The database is write-heavy
- RPO is measured in minutes
- Restore speed matters
- A bad migration must be recoverable
- Accidental deletion risk is high
- The app processes financial, customer, or operational records
- The team needs recovery to a specific moment
These methods require more operational knowledge when self-hosted. They also require retention planning, monitoring, and restore testing.
This is one reason managed databases are attractive for small teams. A managed database can reduce the amount of host-level backup and recovery work the team has to own.
:::cta Compare Raff Managed Databases Use Raff Managed Databases when your SaaS database needs managed backup, monitoring, and recovery controls without operating the database host yourself. :::
Backup storage should be separate from the database host
A backup stored only on the database server is not enough.
If the database host fails, the disk is lost, the server is compromised, or an operator deletes the wrong directory, local-only backups may disappear with the system they are supposed to protect.
A safer pattern is:
Database ↓ Backup job or managed backup system ↓ Separate backup storage ↓ Restore test environment
For self-hosted databases on Raff VMs, this usually means sending database backups to a separate storage layer such as Raff Object Storage.
Raff Object Storage starts at $7.00/month for the first 100 GB and is S3-compatible at s3.raffusercloud.com.
Object storage is a practical fit for:
- Database dump retention
- Compressed backup archives
- Exported reports
- Long-term backup storage
- Off-server recovery copies
- App upload retention
- Backup files from multiple VMs
The goal is separation. The database host should not be the only place where the database can be recovered from.
Backup security matters as much as backup frequency
Database backups often contain the same sensitive data as production.
That means backup files need access control, encryption where appropriate, retention limits, and credential discipline. A backup strategy that creates unprotected copies can increase risk.
OWASP's Database Security Cheat Sheet recommends regular database backups and says backups should be protected with appropriate permissions and ideally encrypted: OWASP Database Security Cheat Sheet.
For SaaS apps, review these controls:
- Store backups outside the database host.
- Restrict who can list, download, or delete backups.
- Use separate credentials for backup writing where possible.
- Avoid using broad admin credentials inside backup scripts.
- Protect environment variables and secrets.
- Encrypt backups when the data requires it.
- Keep backup retention intentional.
- Log backup creation and deletion.
- Rotate credentials if exposure is suspected.
- Do not put production backups in public buckets.
- Do not copy production data into developer laptops without controls.
A backup is not just a recovery asset. It is also a sensitive data copy.
Managed database backups and self-hosted backups have different responsibility models
The right backup strategy depends on who operates the database.
A managed database changes the responsibility model. The provider handles more of the host-level database operations. The customer still needs to understand retention, restore options, access control, application-level mistakes, and export needs.
A self-hosted database gives you more control but also more operational responsibility.
| Area | Managed database | Self-hosted database on VM |
|---|---|---|
| Host maintenance | Provider handles more | Your team handles it |
| Backup scheduling | Usually built into service | Your team designs it |
| Restore workflow | Service-defined tools | Your team documents it |
| Point-in-time recovery | Depends on service features | Your team configures logs/archives |
| Database tuning | Less host-level control | More control |
| Extensions/custom config | Depends on service | Full control |
| Backup storage | Usually integrated | Your team chooses destination |
| Restore testing | Still your responsibility | Fully your responsibility |
| Application-level mistakes | Still your responsibility | Still your responsibility |
Managed does not mean "no responsibility." It means less host-level database work.
Self-hosted does not mean unsafe. It means the team must be disciplined about backups, monitoring, updates, access, and restores.
For the full trade-off, read Managed vs Self-Hosted Databases.
A practical SaaS backup architecture on Raff
A practical Raff backup architecture depends on whether the database is managed or self-hosted.
For a managed database path:
Raff VM for app ↓ private access Raff Managed Database ↓ Managed backup / restore controls ↓ Optional exports to Object Storage for business retention
This path fits SaaS teams that want database operations handled for them.
For a self-hosted database path:
Raff VM for app ↓ private access Raff VM for database ↓ Database-aware backup job ↓ Raff Object Storage backup bucket ↓ Restore test VM or staging environment
This path fits teams that need full control over database version, extensions, configuration, and backup tooling.
For both paths, keep the app server replaceable. The app VM should not be the only source of truth for database data or uploaded files.
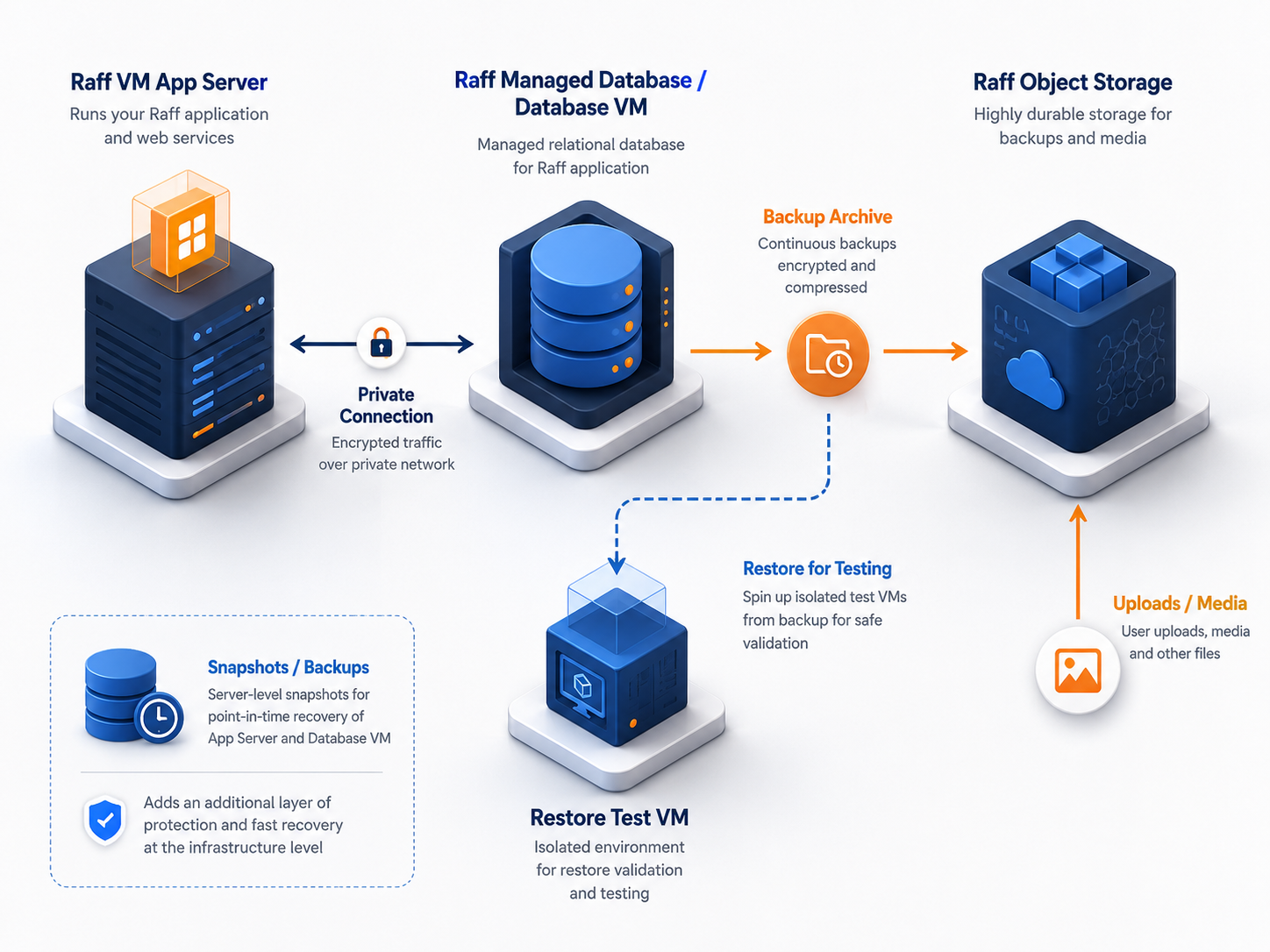
A production Raff setup often separates the layers:
Raff VM = app runtime and workers Raff Managed Database or database VM = structured records Raff Object Storage = uploads, exports, media, and backup archives Snapshots/backups = server-level recovery support
That separation makes recovery easier because each data type has a clear home.
:::cta Explore Raff Object Storage Use Raff Object Storage for database backup archives, exports, and retention copies that should live outside the database server. :::
Backup frequency should match the data change rate
Do not copy another company's backup schedule without understanding your own data.
Backup frequency should reflect how often important data changes and how much of that data the business can lose.
Use this starting framework:
| SaaS stage | Data risk | Practical starting point |
|---|---|---|
| Prototype | Low | Manual or daily backup may be enough |
| Internal tool | Low to medium | Daily backup plus tested restore |
| Early production | Medium | Daily backup plus pre-migration backups |
| Paying SaaS | High | Daily backup plus shorter RPO for important databases |
| Write-heavy SaaS | High | Continuous archiving or managed point-in-time recovery |
| Regulated or critical app | Very high | Formal RPO/RTO, retention, access control, and restore drills |
A small app with a few records per day does not need the same strategy as a billing system with constant writes.
But once customers depend on the data, every backup schedule needs an answer to this question:
If the database disappeared right now, what is the newest data we would lose?
If the answer is unacceptable, the backup frequency is too low.
Retention should protect against both recent and delayed failures
Retention is how long backups are kept.
A common mistake is keeping only the most recent backup. That helps with server failure, but it may not help with delayed discovery.
Some incidents are noticed late:
- A bad migration corrupted data three days ago.
- A bug deleted records last week.
- A customer noticed missing data after the next billing cycle.
- A background job overwrote fields quietly.
- An import created duplicate records.
- A compromised credential was used over time.
A backup strategy should keep multiple restore points.
A practical retention pattern might include:
- Frequent recent backups for short-term recovery
- Daily backups for recent history
- Weekly backups for medium-term rollback
- Monthly backups for longer retention
- Pre-migration backups before risky changes
- Separate retention rules for production and staging
The exact policy depends on the product, compliance needs, storage cost, and customer expectations.
Retention should not be infinite by accident. Old backups can create security and privacy risk if they contain customer data that should no longer be retained.
Restore testing is the part teams skip
A backup strategy is incomplete until restore has been tested.
The restore test proves that:
- The backup file exists.
- The backup is readable.
- Credentials work.
- The restore command is known.
- The target database can start.
- The app can connect.
- The restored data is usable.
- The recovery time is acceptable.
- The team knows who does what.
Do not wait for an incident to discover the restore process.
A simple restore drill can be done in a separate environment:
Backup archive ↓ Restore into test database ↓ Run basic app checks ↓ Record restore time and problems
Track:
- Backup size
- Backup age
- Restore duration
- Missing permissions
- Tooling errors
- App connection problems
- Data validation checks
- Final recovery notes
If the restore takes four hours and your RTO is one hour, the backup exists but the strategy fails.
Database migrations need special backup treatment
Database migrations are one of the most common SaaS recovery risks.
A code rollback is usually easier than a database rollback. Once a migration changes schema or data, reverting can be difficult. A migration can drop columns, rewrite records, change indexes, backfill incorrectly, or lock tables longer than expected.
Before risky migrations:
- Create a pre-migration database backup.
- Confirm the backup completed.
- Confirm where the backup is stored.
- Estimate restore time.
- Define rollback conditions.
- Run the migration in staging first.
- Check database size and lock behavior.
- Document who can approve rollback.
- Avoid running destructive migrations casually.
- Keep app and database deployment order clear.
A pre-migration backup is not a substitute for good migration design, but it gives the team a safer recovery point.
For production launch readiness, pair this with the Production VPS Checklist Before Launching a SaaS App.
App uploads should not depend on database backups
User uploads and database records should have related but separate recovery plans.
A SaaS app often stores upload metadata in the database and stores file bodies in object storage. The database knows who owns the file, what the file is called, and which object key points to it. Object storage stores the actual file.
That means recovery needs both sides:
Database backup = metadata and relationships Object storage retention = actual files
If you restore the database to yesterday but object storage has deleted files from today, user experience can break. If object storage retains files but the database loses the metadata, files may become orphaned.
Plan uploads as a pair:
- Database stores metadata.
- Object storage stores file bodies.
- Retention policies are aligned.
- Delete behavior is defined.
- Restore procedure includes consistency checks.
- Object keys are stored safely.
- Access permissions are recoverable.
For the full file-storage decision, read App Uploads: VM Disk vs Object Storage.
The database backup checklist
Use this checklist before trusting a SaaS database backup strategy.
- Production database owner is defined.
- RPO is written down.
- RTO is written down.
- Backup frequency matches RPO.
- Restore process can meet RTO.
- Backups are stored outside the database host.
- Backup storage access is restricted.
- Backup credentials are not broad admin credentials.
- Backup files are encrypted when the data requires it.
- Retention policy includes more than only the latest backup.
- Pre-migration backups are created before risky changes.
- Restore has been tested in a separate environment.
- Restore time is measured.
- Backup failures trigger alerts.
- Backup size is monitored.
- Backup age is monitored.
- Database logs or WAL/binlogs are retained if point-in-time recovery is required.
- App uploads have a separate storage and retention plan.
- The team knows who performs restore.
- The team knows who approves rollback.
- The recovery plan is documented.
If no one has restored the backup, treat the strategy as unproven.
Common mistakes to avoid
Treating VM snapshots as the only database backup
Snapshots are useful, but they are not always enough for database recovery.
Use database-aware backups for production data, especially when restore accuracy, point-in-time recovery, or migration rollback matters.
Keeping backups on the same server
Local-only backups can disappear with the database host.
Store backups outside the database VM or use managed database backup controls.
Not testing restore
A backup that has never been restored is not a proven recovery plan.
Run restore drills before customers depend on the system.
Backing up uploads only through the database
Large file bodies usually belong in object storage, not the database.
Database backups should protect structured records and upload metadata. File retention should be planned separately.
Letting backup retention grow forever
Old backups can become a security and privacy risk.
Keep retention intentional. Store what the business needs, protect it properly, and delete what should not be retained.
Using one backup policy for every environment
Production, staging, development, and test databases do not need identical backup policies.
Production needs the strongest recovery plan. Development copies should be controlled and limited, especially when they include customer data.
Ignoring backup alerts
Silent backup failure is dangerous.
Monitor backup age, backup success, backup size, and restore test results.
Database backup strategy should match SaaS risk
A good database backup strategy for SaaS apps starts with risk, not tooling.
Define RPO and RTO. Separate database backups from VM snapshots. Store backups away from the database host. Protect backup access. Test restore. Treat migrations as recovery events. Keep uploads and database records in separate but aligned recovery plans.
For Raff teams, the clean path is straightforward: use Raff Managed Databases when database operations should be handled for you, use Raff VMs when you need self-hosted control, and use Raff Object Storage for backup archives, exports, uploads, and retention copies.
A backup is not the goal. A working restore is the goal.
Review Raff pricing, then choose the database, storage, and backup pattern your team can operate safely for the next 6-12 months.
:::cta Compare Raff Managed Databases Choose Raff Managed Databases when your SaaS team wants production database recovery controls without managing the database host. :::