

A production VPS checklist is a server readiness framework that helps SaaS teams verify sizing, access, backups, monitoring, and storage before launch.
For a SaaS app, "the server is online" is not the same as "the server is ready for production." Raff Technologies operates 10,000+ VMs from Vint Hill, Virginia, for teams that want production cloud infrastructure without hyperscaler complexity. Before real users arrive, your VPS needs enough headroom, a controlled traffic path, tested recovery, and a clear decision on what belongs on the VM disk.
This guide is part of our VPS for application hosting coverage. It focuses only on VPS and server readiness, not product launch tasks like billing, onboarding emails, analytics, or marketing launch plans.
A production VPS checklist is narrower than a launch checklist
A production VPS checklist should answer one question: can this server safely handle the first real users of the SaaS app?
A general launch checklist covers product, support, payments, onboarding, analytics, legal pages, status pages, and customer communication. Those matter, but they are not the same as server readiness. This guide is intentionally narrower.
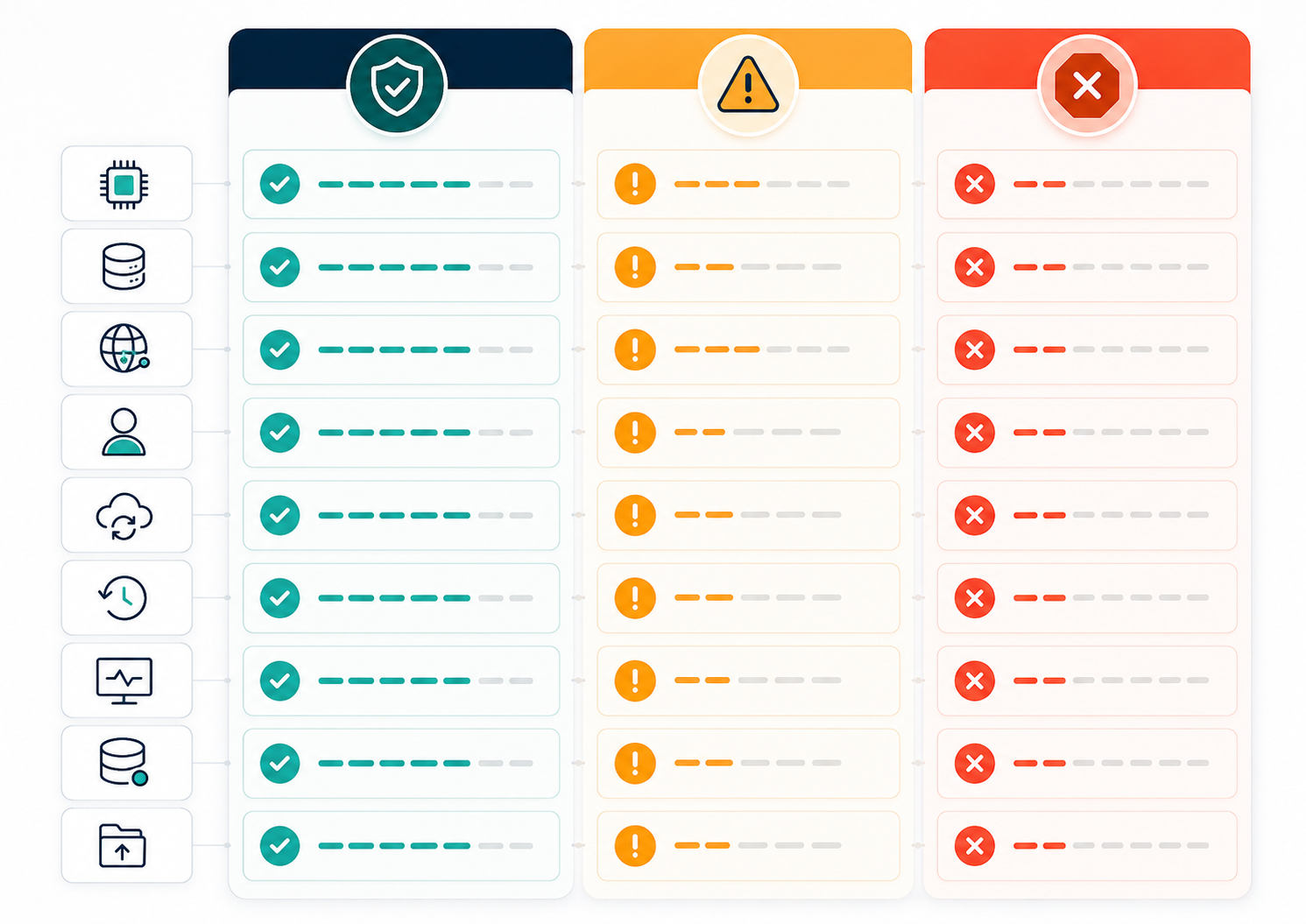
A launch-ready production VPS should have:
- Enough CPU and RAM headroom for normal traffic and short spikes
- Enough disk capacity for logs, deploys, temporary files, database growth, and uploads
- A traffic path that is easy to understand
- Firewall rules that expose only required services
- Admin access that belongs to real people, not forgotten keys
- Backups or snapshots that have been tested through restore
- Monitoring that can show failure before customers report it
- A storage plan for user uploads, logs, and database files
- A resize or split plan if the app outgrows one server
This matters most for small SaaS teams because the first production server often carries too many responsibilities. It runs the app, database, background worker, reverse proxy, logs, cron jobs, and uploads. That setup can be fine for an MVP, but only when the risk is visible.
The goal is not to overbuild before launch. The goal is to know whether you can launch, what you need to fix first, and what should move off the VM later.
The production VPS checklist separates launch, fix, and redesign decisions
The checklist below uses three decisions: launch now, fix before launch, or redesign before launch.
"Fix before launch" means the architecture can stay the same, but the current server state is not ready. "Redesign before launch" means the server is carrying a risk that a bigger VM alone may not solve.
| Area | Ready to launch | Fix before launch | Redesign before launch |
|---|---|---|---|
| CPU and RAM | Normal test traffic stays below 60-70% | Short spikes exceed 70% but recover quickly | Steady load is already above 70% |
| Disk capacity | 30%+ free disk after deploy, logs, and test data | Free space is low or alerts are missing | Uploads, logs, or database growth can fill the VM |
| Traffic path | DNS, proxy, app port, and TLS path are documented | Temporary domains or ports still exist | Users can bypass the intended web entry point |
| Public ports | Only required ports are open | Old test ports or admin ports remain | Database, admin UI, or internal services are public |
| Access | Named users, SSH keys, and admin access are reviewed | Shared access still exists | Unknown keys, users, or API tokens exist |
| Backups | Backup exists and restore was tested | Backup exists but restore is untested | No recovery path exists |
| Rollback | Last known-good deploy or snapshot path exists | Rollback depends on manual memory | No rollback owner or restore point exists |
| Monitoring | CPU, RAM, disk, uptime, and app health are visible | Basic uptime exists only | No alert reaches the team |
| Database | Data fits the VM and backup plan | Same-VM database is acceptable but near limits | Database needs separate storage or a separate server |
| Uploads | Upload path is planned and backed up | Uploads are on disk temporarily | User files can grow without limit |
A SaaS VPS is not launch-ready if steady CPU or memory usage already exceeds 70% before real users arrive.
That number is not a universal law. It is a practical warning line. You need room for signups, background jobs, deploys, database queries, abuse, and traffic bursts. A server that looks fine at 95% CPU in staging is already too close to failure for launch.
Server sizing and traffic path decide launch risk
Server sizing should start from workload behavior, not from the cheapest plan that boots the app.
For a small SaaS MVP, a single VPS can be enough when the app has modest traffic, a small database, limited background jobs, and predictable uploads. It becomes risky when multiple heavy workloads fight for the same CPU, RAM, disk, or network path.
Review these sizing areas before launch.
| Resource | What to check | Launch-ready sign | Risk sign |
|---|---|---|---|
| CPU | App requests, workers, scheduled jobs, image processing | Short spikes recover quickly | CPU stays high during normal usage |
| RAM | App process, database, cache, worker, OS | Free memory remains after test traffic | Swapping, out-of-memory kills, or database pressure |
| Disk | OS, app releases, logs, database, uploads, temp files | 30%+ free space after test data | Logs or uploads grow without limits |
| Network | Web traffic, API traffic, downloads, object transfer | Traffic path is clear | Users bypass proxy or hit app port directly |
| Database | Query load, backups, indexes, migrations | Database fits launch workload | Migrations or queries block the app |
| Background jobs | Email, billing, exports, queues, cron jobs | Jobs finish inside expected windows | Jobs pile up during traffic |
The traffic path should be simple enough that any engineer on the team can explain it in one minute.
For example:
DNS -> reverse proxy -> app process -> database
or:
DNS -> reverse proxy -> app process -> object storage for uploads
The dangerous version is the one nobody can explain. Maybe the app is reachable on both port 3000 and 443. Maybe the old staging domain still points at production. Maybe a temporary admin dashboard is still public. Maybe the database accepts public connections because it was easier during setup.
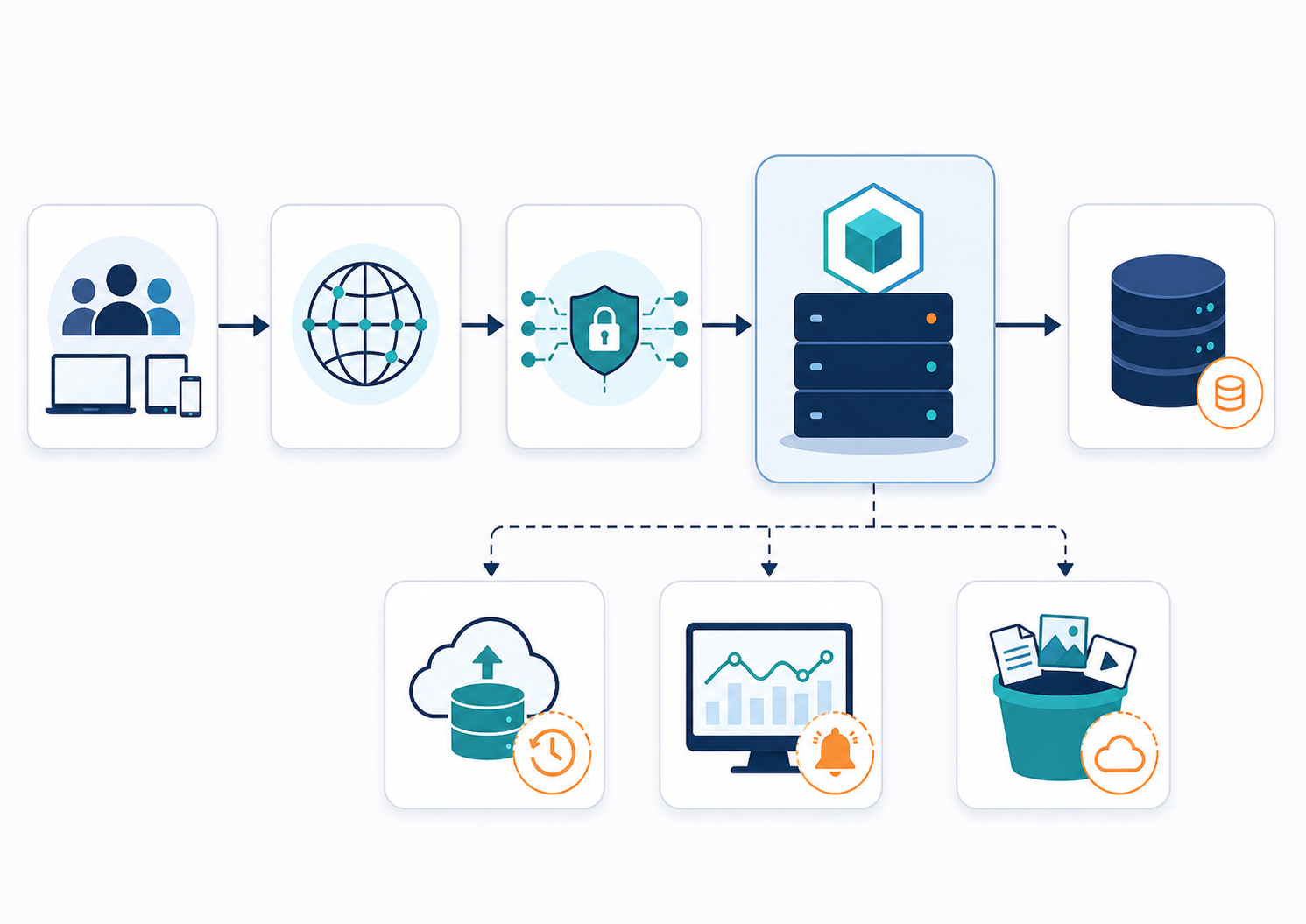
Those are not abstract risks. They become outages and security incidents when real users arrive.
A production VPS should have one intended public entry point for users, one controlled admin path for the team, and no accidental public services.
A single production VPS works when failure modes are controlled
A single VPS can be the right production starting point for a SaaS MVP when the team understands what can fail and how to recover.
Use one production VPS when the app is early, traffic is predictable, the database is small, uploads are limited, and the team can restore service from a tested backup or snapshot. This keeps the launch simple and lets the team learn from real usage before adding more moving parts.
Use a larger VPS before launch when test traffic already shows CPU, RAM, or disk pressure, but the architecture is still simple. Resizing is the right fix when the app only needs more headroom and the database, uploads, and background jobs are still manageable.
Split services before launch when the failure mode changes. If user uploads can fill the VM disk, move uploads to object storage. If the database is the most important recovery target, give it a separate backup and scaling plan. If background jobs can block user-facing requests, separate the worker path from the web path.
| Decision | Choose it when | Avoid it when |
|---|---|---|
| Single VPS | MVP traffic is modest and recovery is tested | Database, uploads, and workers are already near limits |
| Larger VPS | The same architecture needs more CPU, RAM, or disk | Growth is caused by storage or database separation needs |
| Split architecture | One component creates a different failure or recovery risk | The team cannot operate the added complexity yet |
This is the practical difference between simple and fragile. A single VPS is simple when it has headroom, backups, monitoring, and a storage plan. It is fragile when it carries every workload without a recovery path.
Access, firewall, and public exposure need a final review
Access control is one of the easiest production risks to create during launch preparation.
During development, teams add temporary SSH keys, share root passwords, open ports for debugging, and create admin dashboards. Before launch, each shortcut needs a final review. OWASP Top 10:2021 lists broken access control as A01, with more than 318,000 occurrences in its contributed dataset.
For a production VPS, review five areas.
First, check who can access the server. Named team members should have named access. Shared accounts and unknown keys should be removed. If someone left the project, their access should be gone before launch.
Second, check what is public. A SaaS app usually needs HTTP and HTTPS exposed. It may need SSH available to a restricted source. It should not expose the database, internal admin panel, queue dashboard, cache, or development server to the public internet.
Third, check the firewall. Firewall rules should describe the intended traffic model. If a port was opened for testing, close it. If a database needs to be reached only by the app server, do not make it public.
Fourth, check secrets. Environment variables, API keys, database passwords, and object storage credentials should not live in Git history, public repos, screenshots, or shared chat messages. Rotate exposed secrets before launch instead of hoping they were not copied.
Fifth, check the admin path. Teams need a way to manage production, but that path should be deliberate. A private IP path, VPN, bastion, or tightly scoped SSH rule is safer than a public dashboard protected by a weak password.
The standard is simple: a new engineer should be able to see which services are public, which services are private, and who owns production access.
Backups, rollback, and monitoring must be proven before launch
A backup that has not been restored is only a backup claim.
Before launch, define two recovery numbers:
- Recovery Point Objective: how much data you can afford to lose
- Recovery Time Objective: how long the app can be unavailable while you recover
NIST describes Recovery Point Objective as the point in time to which systems and data must be recovered after an outage. For a SaaS app, that means daily backups may be enough for a demo product, but not for a paid product that stores important customer data.
Use this recovery checklist before launch.
| Area | Ready to launch | Not ready |
|---|---|---|
| VM snapshot | Snapshot exists before major deploy | No restore point before launch |
| Database backup | Backup runs on schedule | Database backup is manual only |
| Restore test | Restore was tested on a separate environment | Backup has never been restored |
| Rollback owner | One person owns rollback during launch | Everyone assumes someone else owns it |
| Deploy record | Last known-good version is clear | No one knows what version is live |
| Monitoring | CPU, RAM, disk, uptime, and app health are visible | Only customer reports reveal issues |
| Alerts | Alerts reach the right person | Alerts go nowhere or to a noisy inbox |
Monitoring should cover the server and the app. Server metrics show CPU, RAM, disk, and network pressure. App metrics show whether users can actually log in, use the product, and complete the core workflow.
A green server does not always mean a healthy SaaS app. The VM can be running while the database is locked, the payment webhook is failing, or the background worker is stuck. That is why a production VPS checklist should include at least one app-level health check, not only infrastructure metrics.
Rollback should also be written down. A rollback plan can be simple: restore a snapshot, redeploy the previous app version, or revert a database migration if it is safe. The exact method depends on your stack. The key point is ownership. During launch, one person should know which rollback path will be used and when to call it.
For the first 24-72 hours after launch, check the same signals more often: CPU, RAM, disk growth, queue depth, error rate, login success, payment or webhook failures, and backup completion. The first production users usually reveal the workload shape that staging could not simulate.
App data should not all stay on the VM disk
The VM disk is the right place for the operating system, application runtime, package cache, and small working files. It is not always the right place for every piece of SaaS data.
Before launch, separate data into four groups:
| Data type | Good default | Why |
|---|---|---|
| App code and runtime | VM disk | Fast local execution and simple deploys |
| Database files | VM disk at first, separate later when needed | Simple MVP setup, but growth and recovery need planning |
| User uploads | Object storage when uploads matter | Prevents user files from filling the server disk |
| Logs and exports | Retention policy, separate storage for long retention | Keeps disk usage predictable |
User uploads deserve special attention. If customers upload images, PDFs, reports, exports, audio, backups, or generated files, those files can outgrow the original VM plan quickly. They also complicate backups. Restoring a VM snapshot is not the same as managing a growing file library.
For a small MVP with a few uploads, VM disk can be acceptable for launch. For a product where uploads are part of the core user experience, plan object storage early. That keeps app compute, user files, and recovery planning separate.
The same logic applies to databases. A database on the same VPS can be fine for early production when load is low, backups are tested, and the team understands the limit. Once the database becomes the most important part of the business, it needs its own recovery and performance plan.
For deeper architecture planning, read Single VM vs Multi-VM Architecture for SaaS Apps and Object Storage vs Block Storage vs VM Disk.
Production VPS readiness on Raff
Raff VM is the main Raff product for teams launching SaaS apps on a production VPS. A typical early setup uses one Linux VM for the app, reverse proxy, background worker, and database, then separates storage or database layers when the product grows.
Raff's CPU-Optimized 2 vCPU / 4 GB VM costs $19.99/month with 80 GB NVMe SSD and unmetered VM traffic.
That plan is a practical reference point for small SaaS apps that need consistent CPU, moderate memory, and enough storage for the app, logs, and early data. Smaller apps can start lower. Heavier apps should size up before launch if test traffic already pushes CPU, RAM, or disk close to the warning range.
Raff also supports snapshots, automated backups, block storage volumes, private networking, firewalls, and object storage. Automated backups include 3 free backup slots per VM, and additional backup or snapshot storage is priced per GB. Object Storage starts at $7.00/month for the first 100 GB and uses an S3-compatible endpoint for app uploads, exports, and media.
At Raff, we use a simple launch rule with small SaaS teams: when the first production server already needs more than 70% of CPU or RAM under realistic traffic, resizing should happen before launch, not after. That threshold is a risk-control line. It leaves room for signup spikes, background jobs, database queries, and deploy-time processes.
This is also why Raff keeps VM bandwidth unmetered. A launch should not force a founder to guess whether a traffic spike will create surprise VM egress fees. The harder decision should be technical readiness: whether the app, database, storage, firewall, backups, and monitoring are ready for real users.
Production VPS readiness turns launch risk into a clear decision
A production VPS checklist helps you make a clear launch decision: launch now, fix first, or redesign before launch. The checklist is not there to slow the team down. It is there to stop small, predictable infrastructure gaps from becoming customer-facing incidents.
Use this guide with the broader VPS for application hosting decision guide, then review cloud server performance bottlenecks if CPU, RAM, disk, or network pressure is already visible.
When your SaaS app is ready for a production VPS, compare Raff VM plans with your launch risk: CPU and RAM headroom, disk growth, backup needs, and whether uploads or databases should move outside the first server.